Obsah:
Způsob 1: Použití automatického nástroje
V Excel je automatický nástroj určený k rozdělení textu do sloupců. Nepracuje v automatickém režimu, takže všechny akce je třeba provádět ručně, předem vybráním rozsahu zpracovávaných dat. Nastavení je však maximálně jednoduché a rychlé na realizaci.
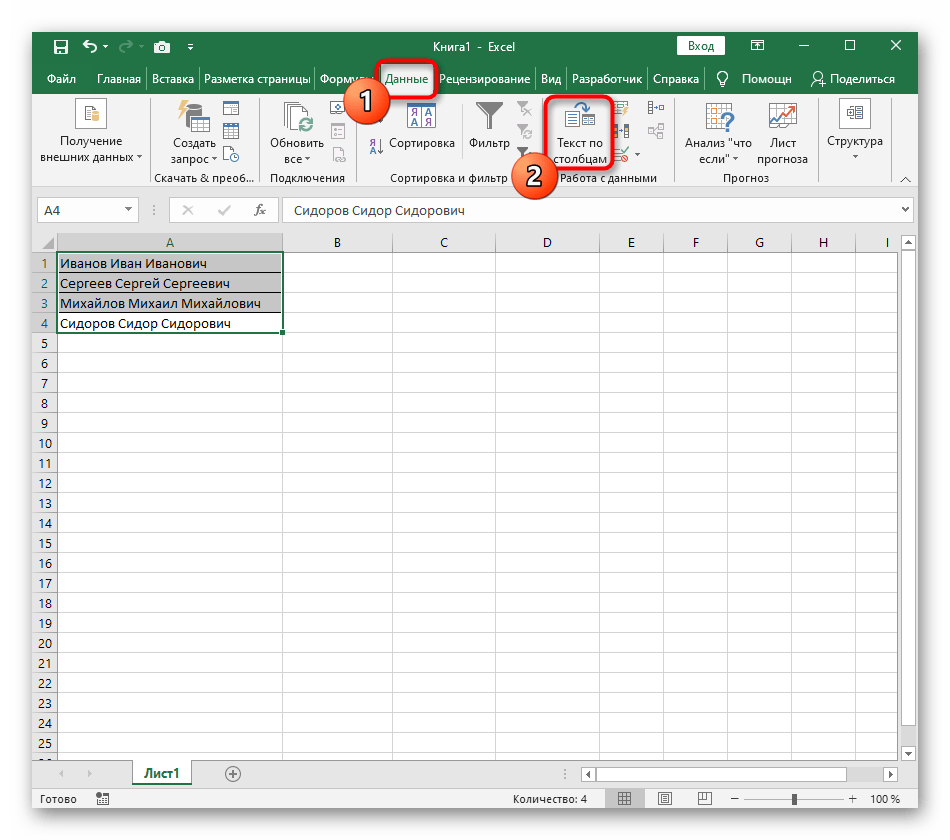
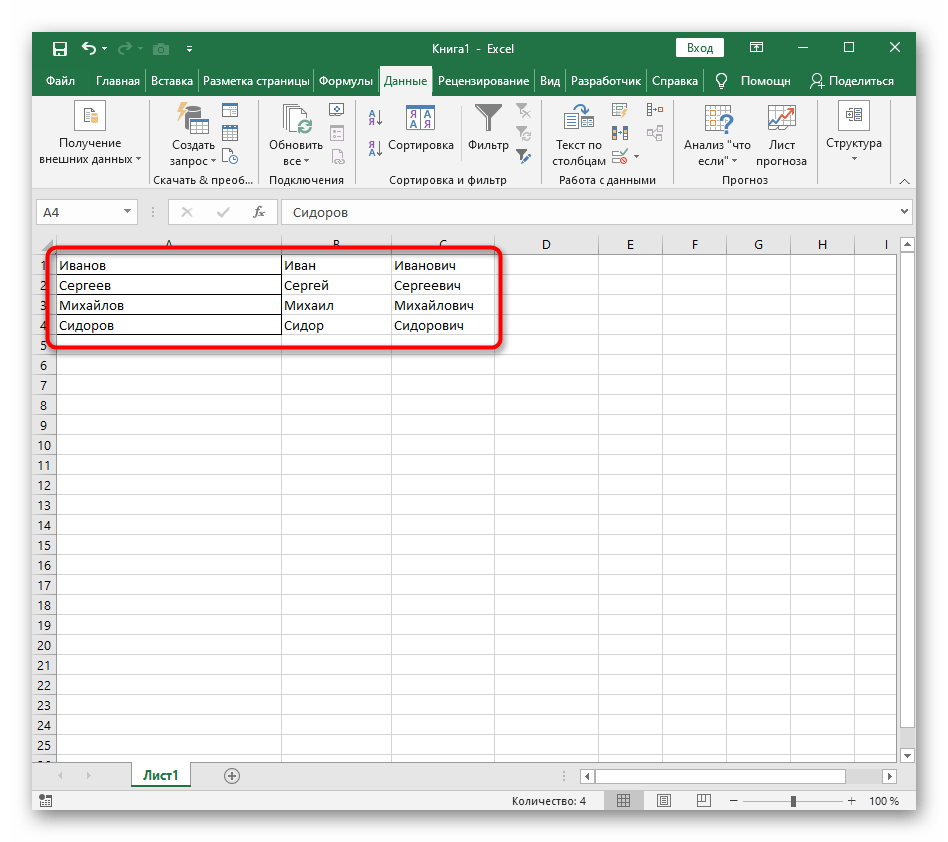
- S podržením levého tlačítka myši vyberte všechny buňky, jejichž text chcete rozdělit do sloupců.
- Poté přejděte na kartu "Data" a klikněte na tlačítko "Text do sloupců".
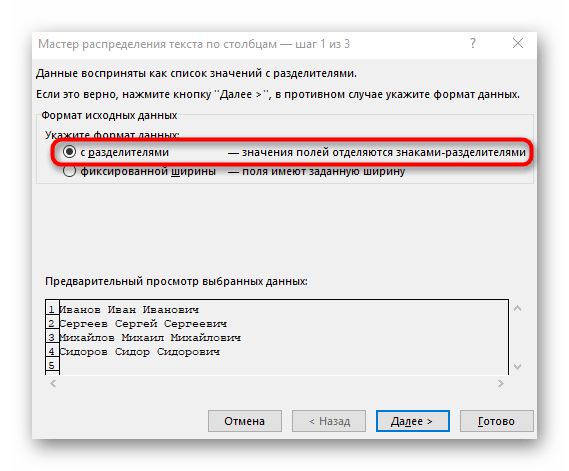
- Objeví se okno "Průvodce rozdělením textu do sloupců", ve kterém je třeba vybrat formát dat "s oddělovači". Oddělovačem je nejčastěji mezera, ale pokud je to jiná interpunkční značka, je třeba ji uvést v dalším kroku.
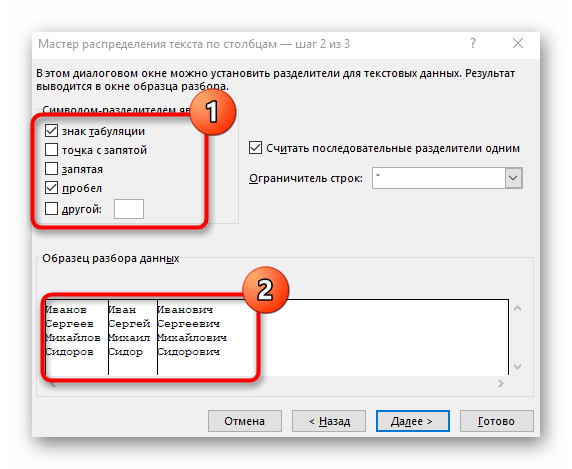
- Zaškrtněte symbol oddělení nebo jej ručně zadejte a poté se seznamte s předběžným výsledkem rozdělení v okně níže.
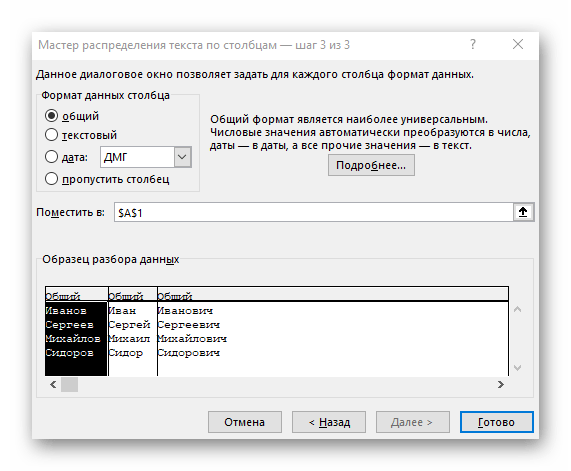
- V závěrečném kroku můžete uvést nový formát sloupců a místo, kam je třeba je umístit. Jakmile bude nastavení dokončeno, klikněte na "Hotovo" pro aplikaci všech změn.
- Vraťte se k tabulce a ujistěte se, že rozdělení proběhlo úspěšně.
Z této instrukce lze vyvodit, že použití takového nástroje je optimální v situacích, kdy je třeba rozdělení provést pouze jednou, přičemž pro každé slovo označíte nový sloupec.Nicméně, pokud se do tabulky neustále přidávají nová data, bude rozdělování tímto způsobem poněkud nepohodlné, proto v takových případech doporučujeme se seznámit s následujícím způsobem.
Způsob 2: Vytvoření vzorce pro rozdělení textu
V Excelu si můžete sami vytvořit relativně složitý vzorec, který umožní vypočítat pozice slov v buňce, najít mezery a rozdělit každé na jednotlivé sloupce. Jako příklad vezmeme buňku, která se skládá ze tří slov oddělených mezerami. Pro každé z nich bude potřeba svůj vzorec, proto rozdělíme způsob na tři etapy.
Krok 1: Rozdělení prvního slova
Vzorec pro první slovo je nejjednodušší, protože se bude vycházet pouze z jedné mezery pro určení správné pozice. Prozkoumejme každý krok jeho vytvoření, abychom získali úplný obrázek o tom, proč jsou určité výpočty potřebné.
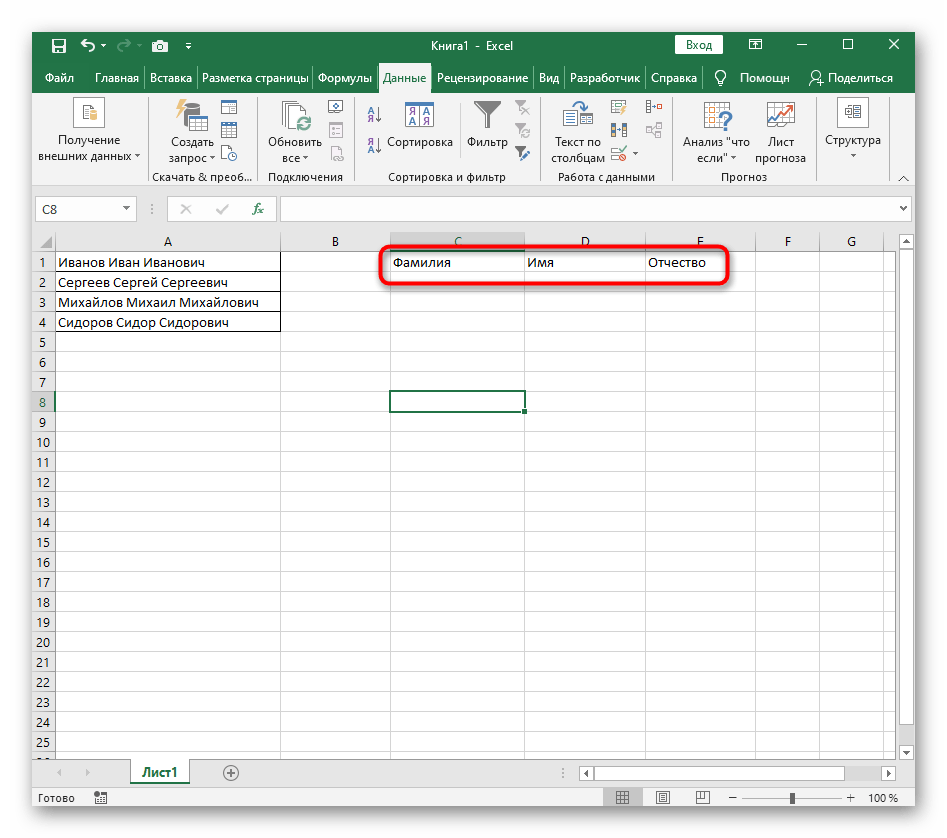
- Pro pohodlí vytvoříme tři nové sloupce s popisky, do kterých budeme přidávat rozdělený text. Můžete to udělat také, nebo tento krok přeskočit.
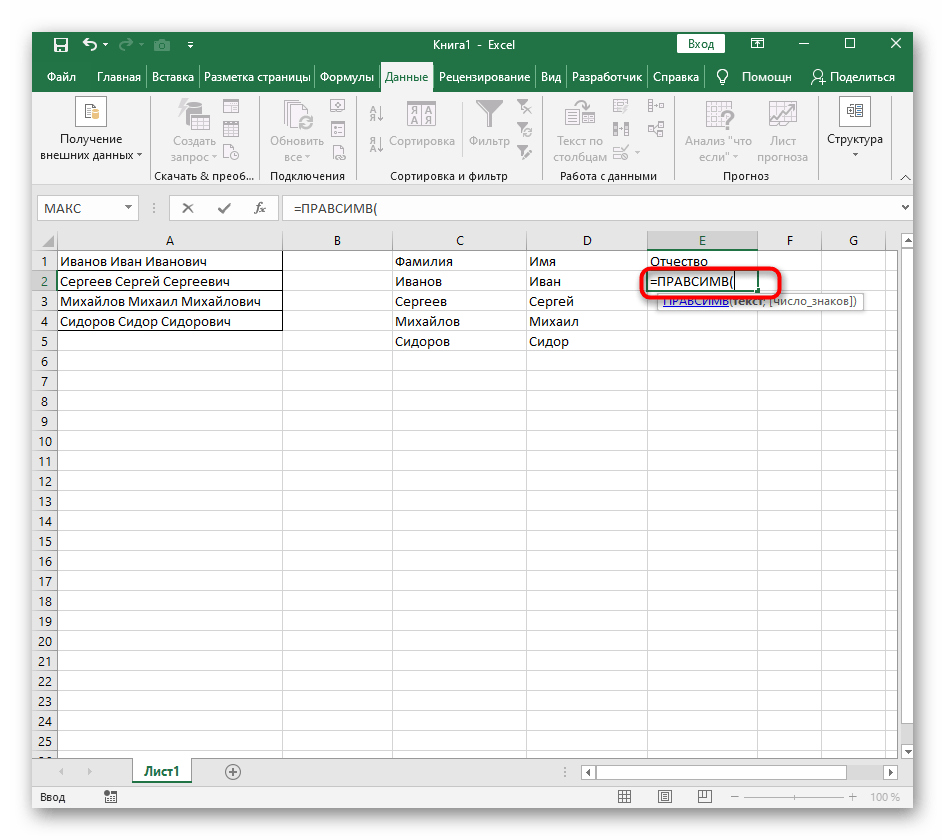
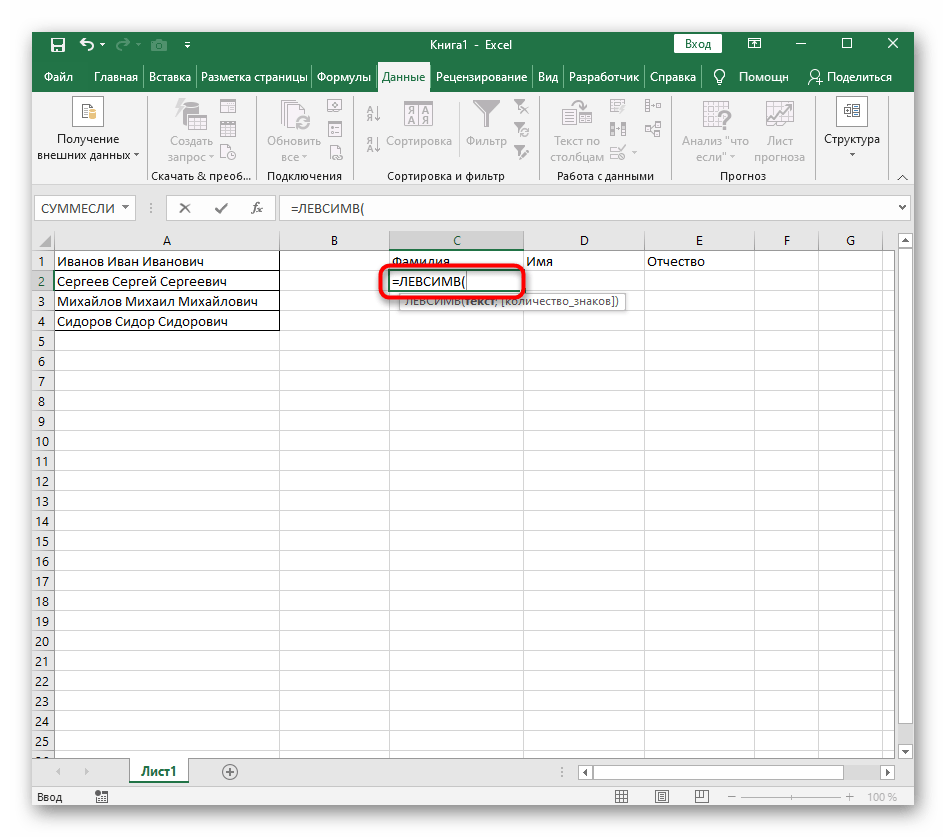
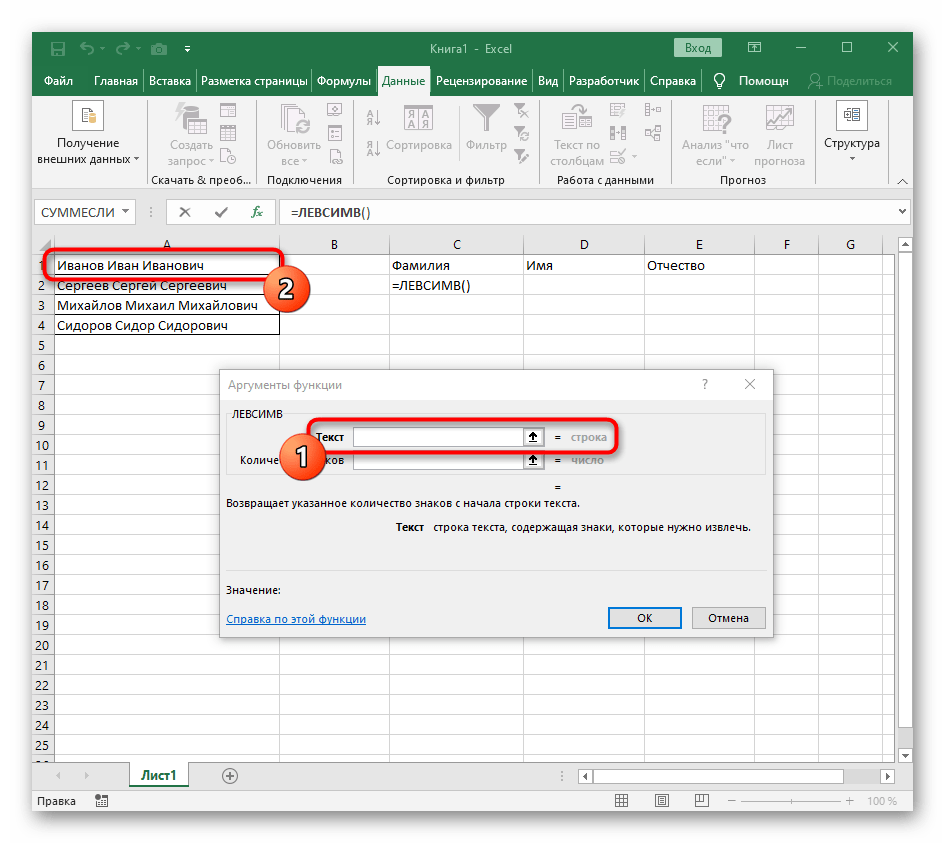
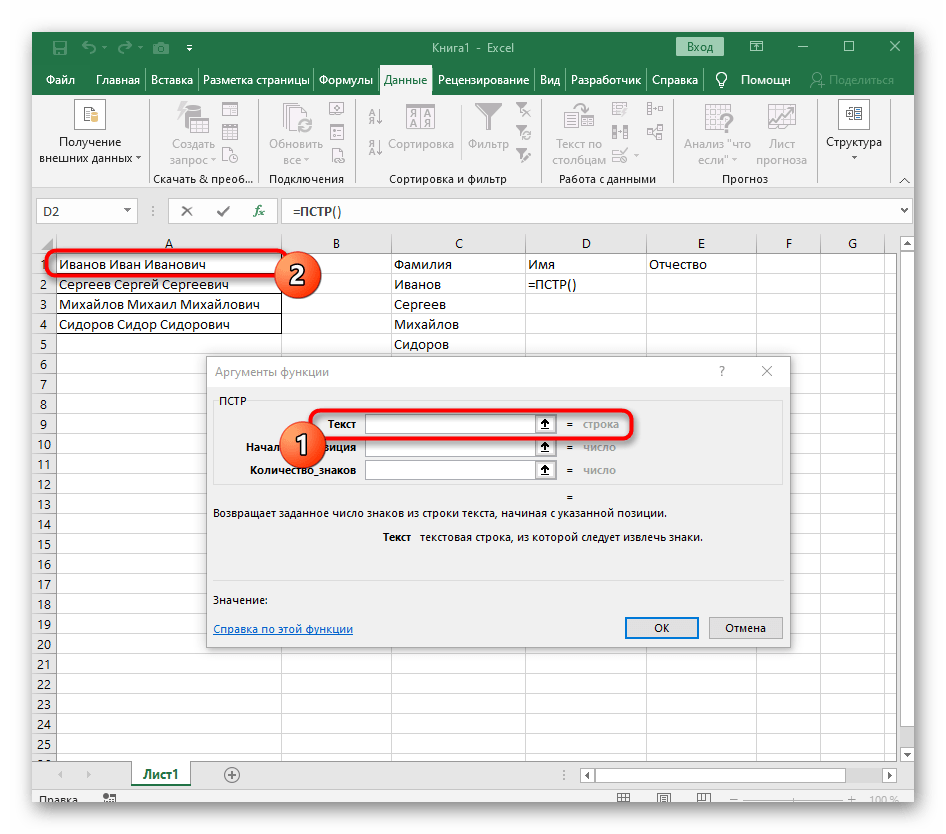
- Vyberte buňku, kde chcete umístit první slovo, a zapište vzorec
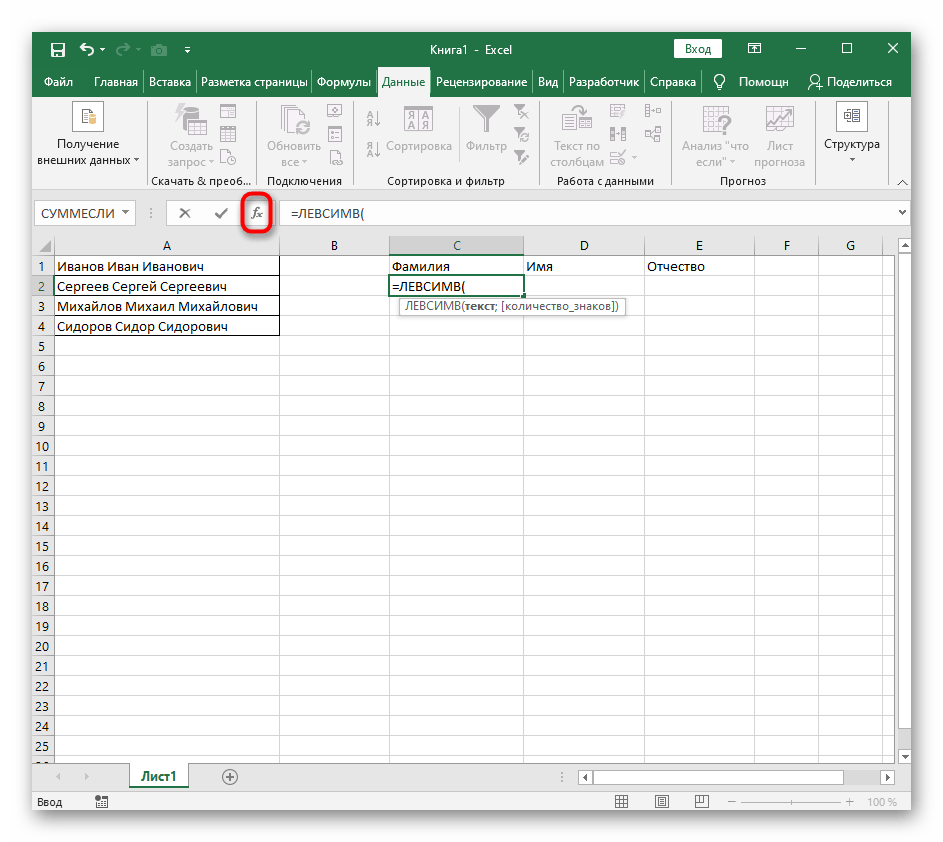
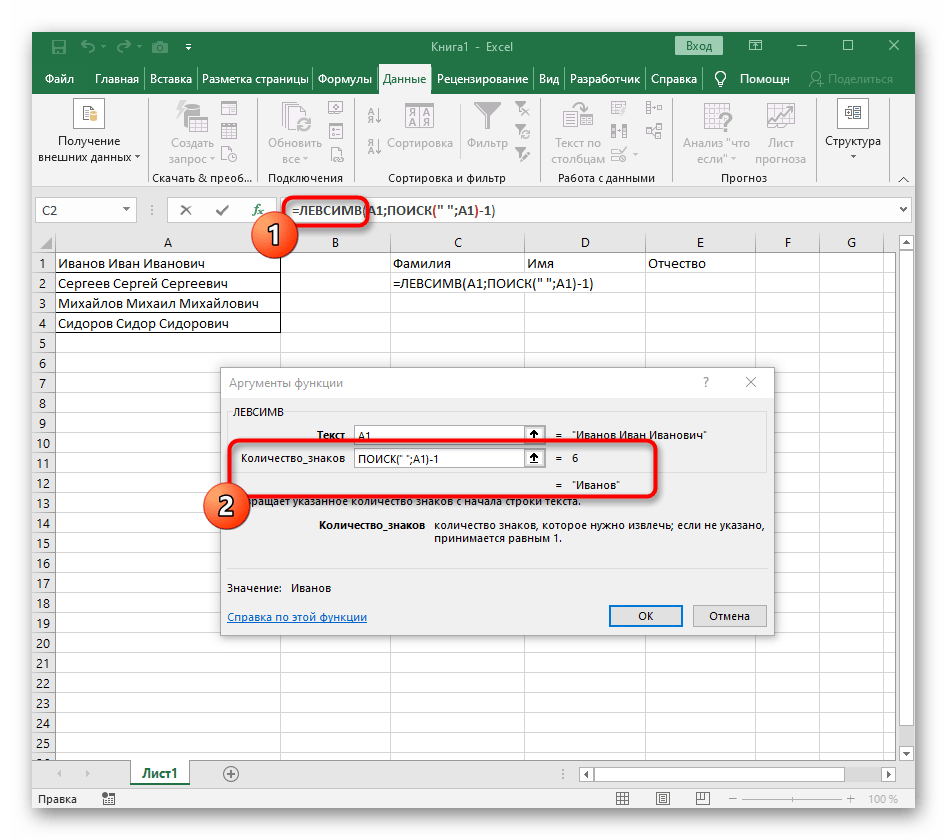
=LEV(. - Poté stiskněte tlačítko "Argumenty funkce", čímž přejdete do grafického okna pro úpravu vzorce.
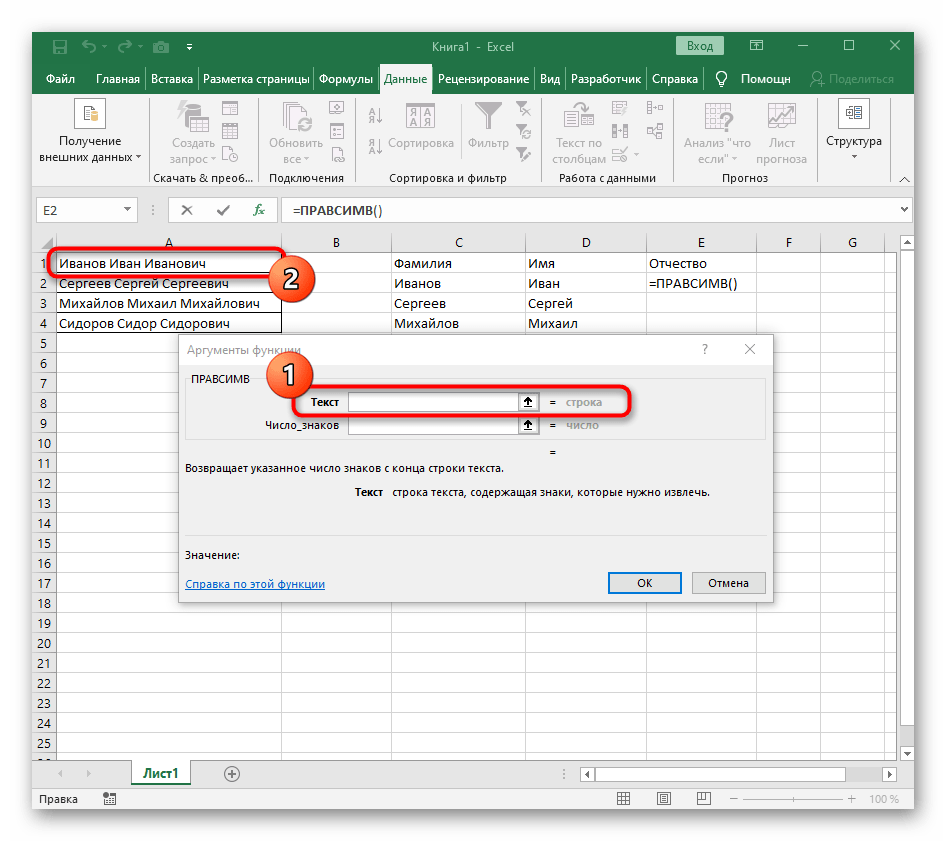
- Jako text argumentu uveďte buňku s textem, kliknutím na ni levým tlačítkem myši v tabulce.
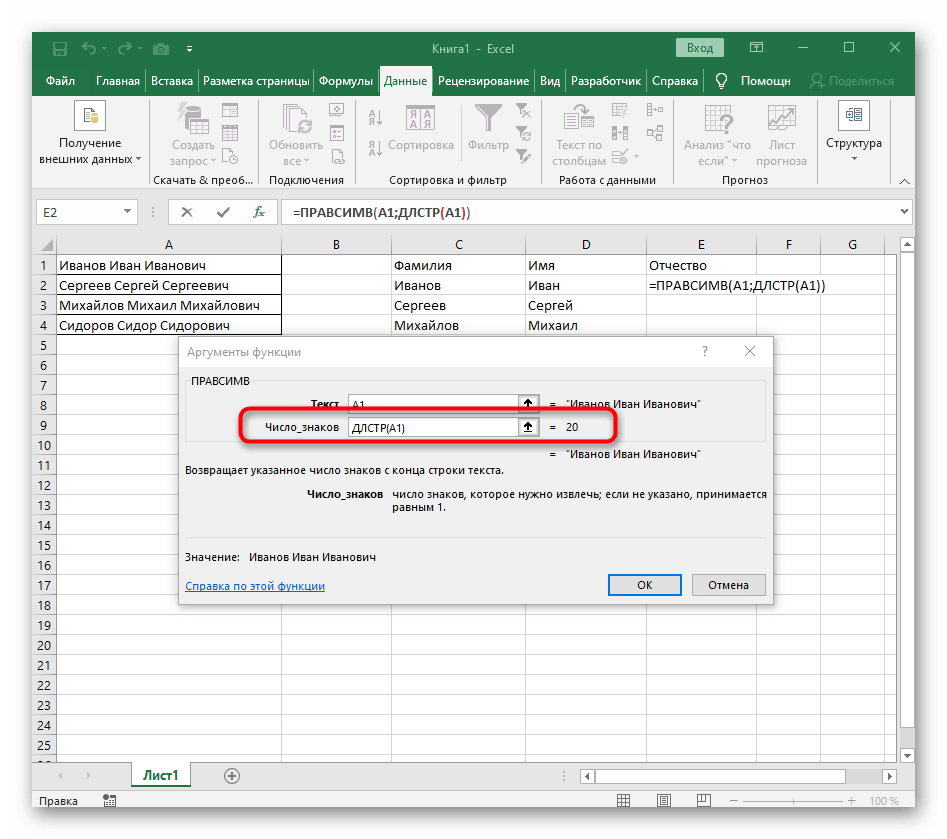
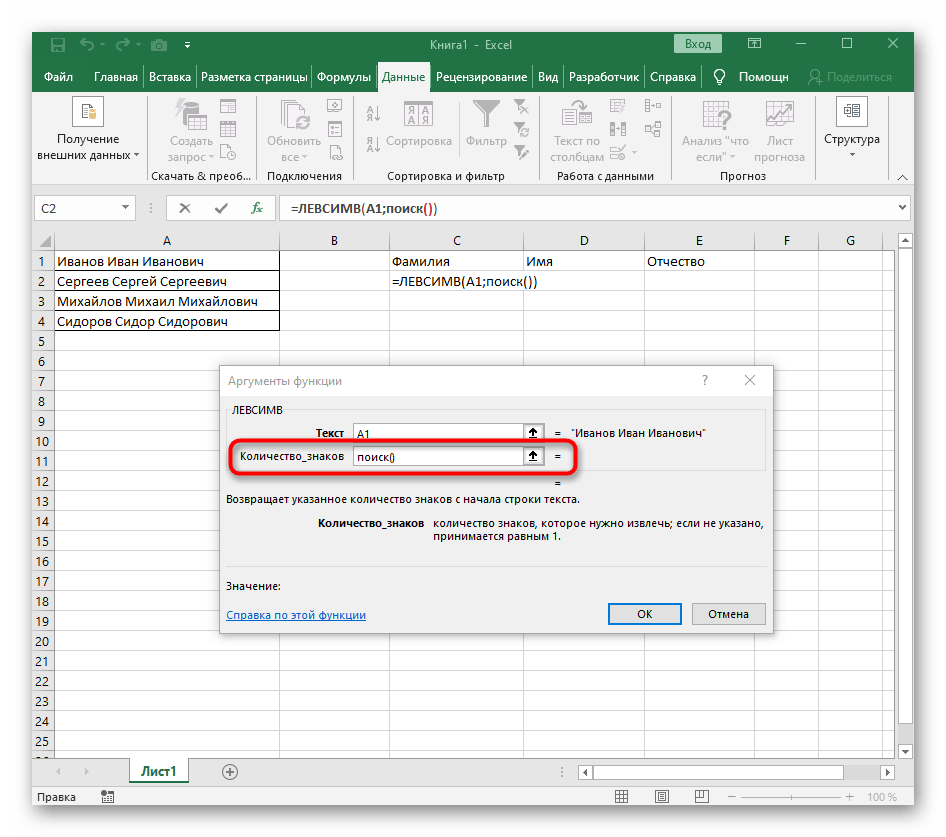
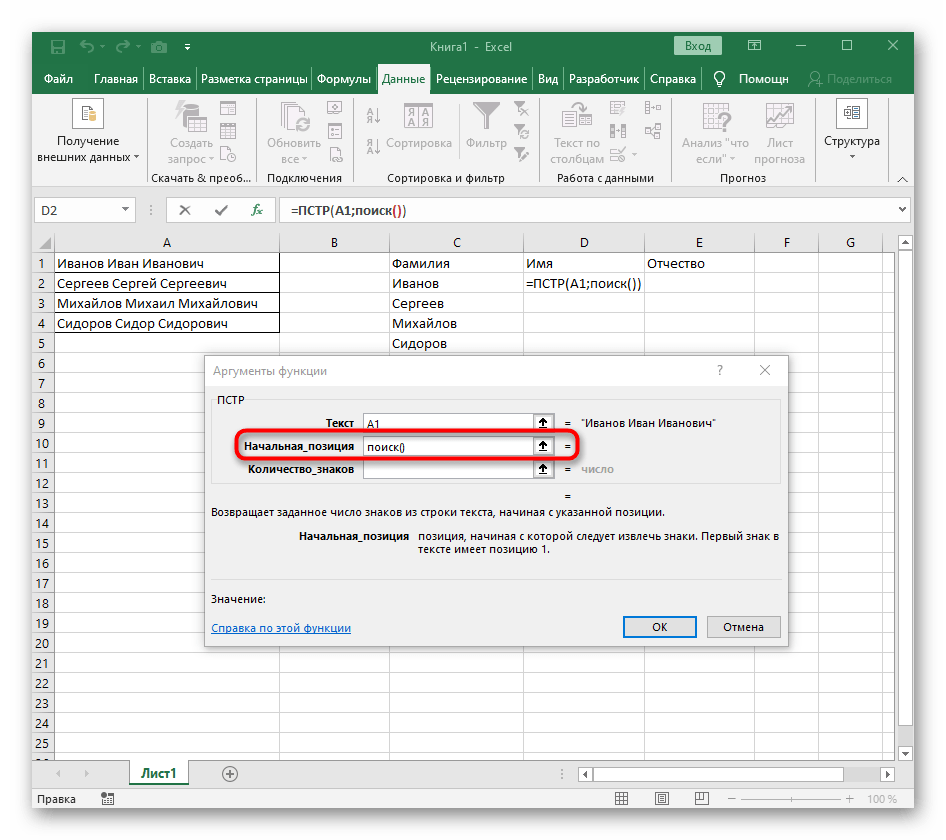
- Počet znaků před mezerou nebo jiným oddělovačem bude třeba spočítat, ale ručně to dělat nebudeme, místo toho využijeme další vzorec —
NAJÍT(). - Jakmile jej zapíšete v tomto formátu, zobrazí se v textu buňky nahoře a bude zvýrazněn tučně. Klikněte na něj pro rychlý přechod k argumentům této funkce.
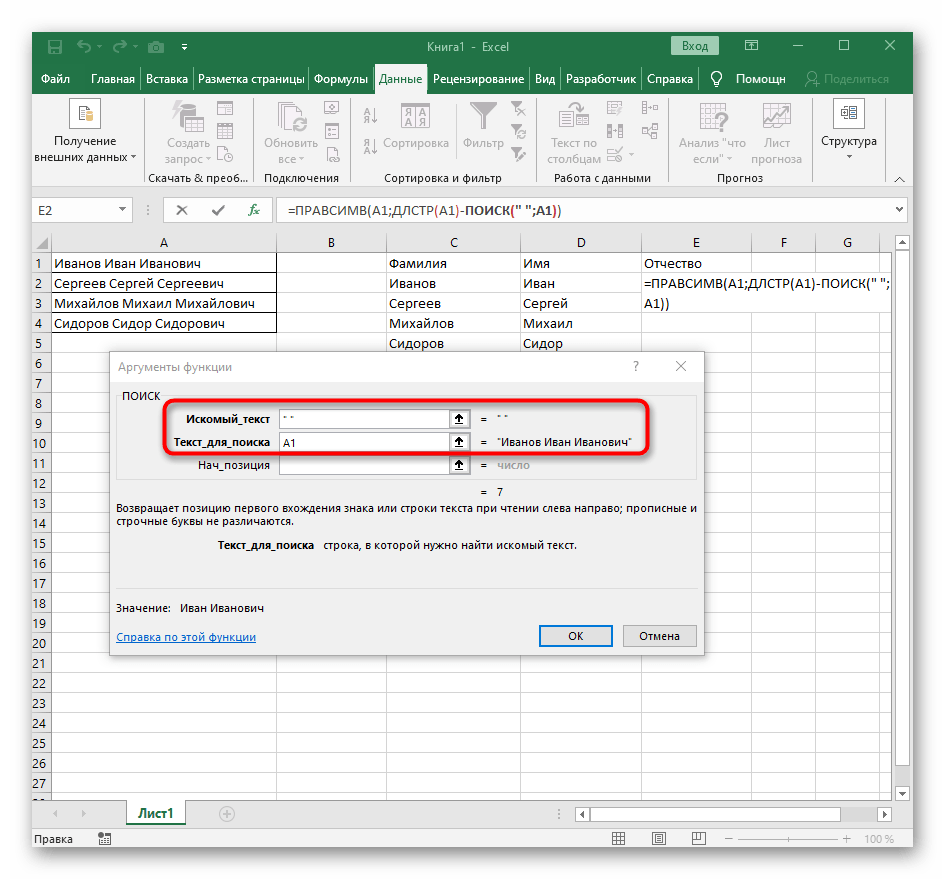
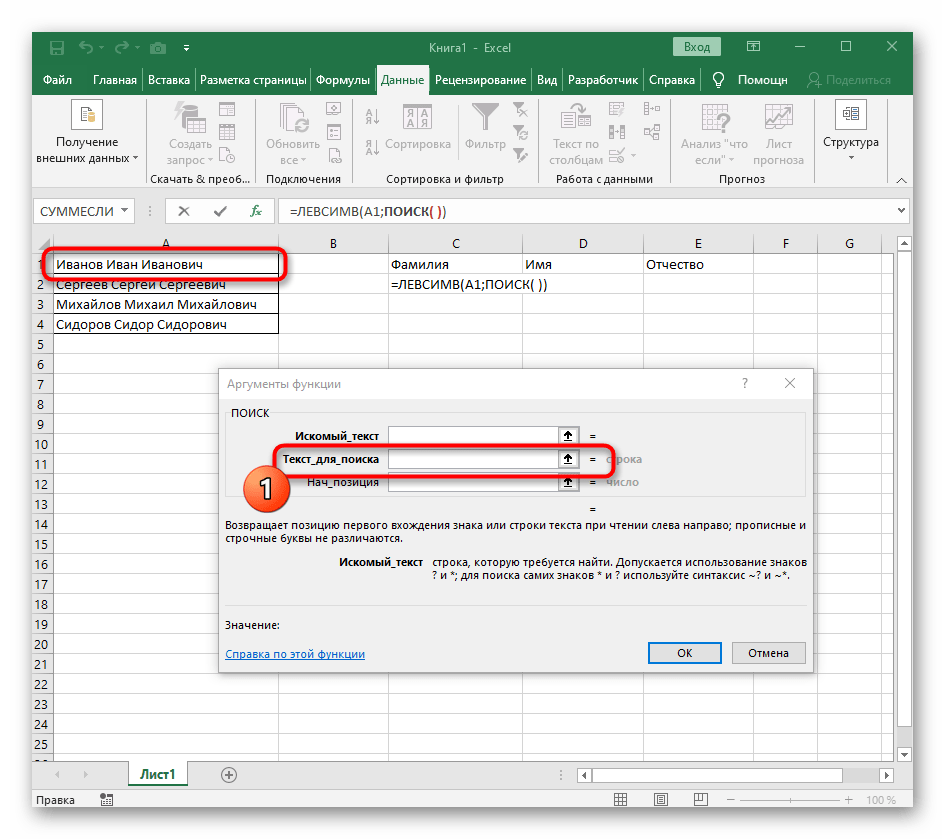
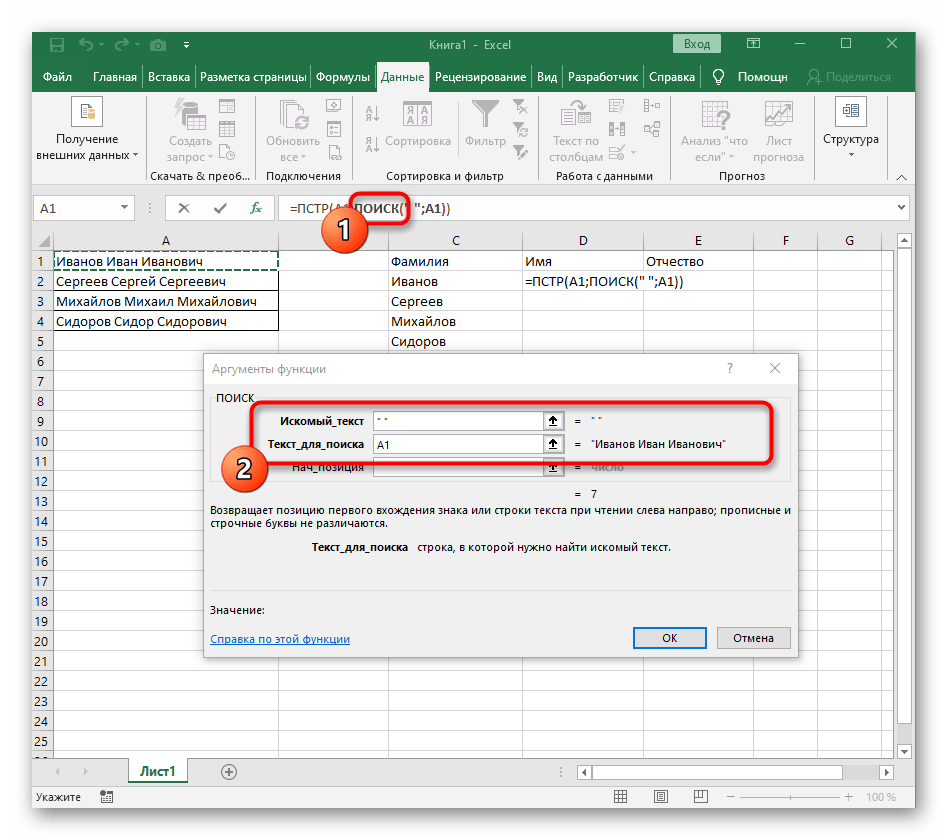
- V poli "Hledaný_text" jednoduše zadejte mezeru nebo používaný oddělovač, protože to pomůže pochopit, kde slovo končí. V "Text_pro_hledání" uveďte stejnou zpracovávanou buňku.
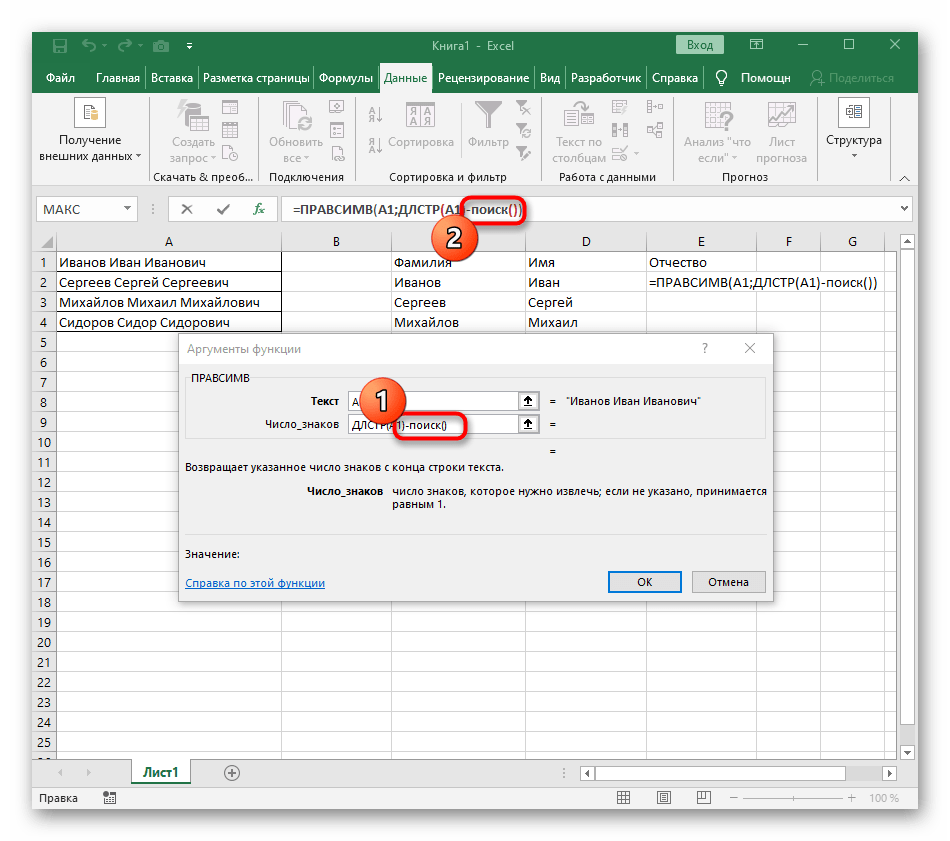
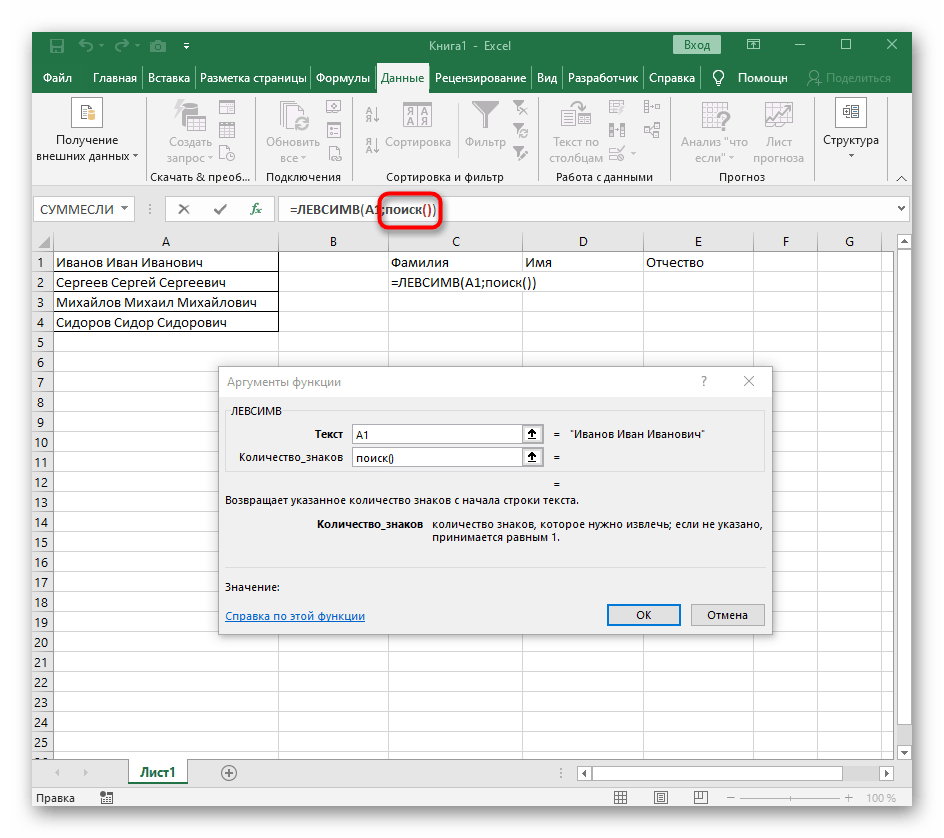
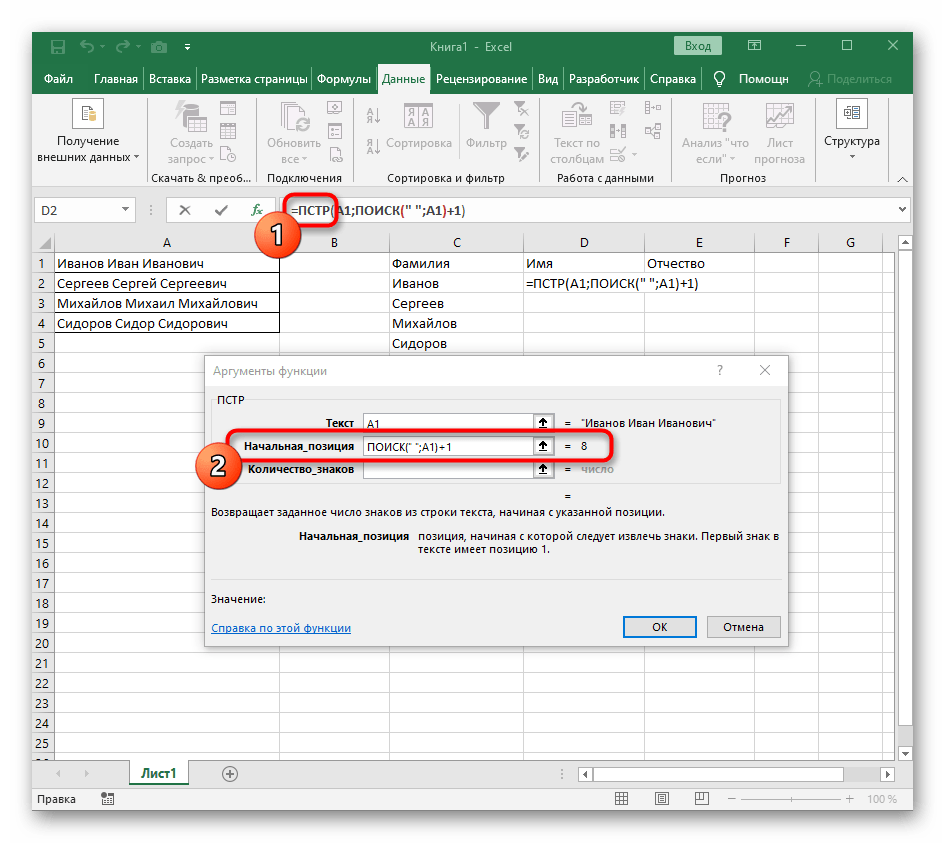
- Klikněte na první funkci, abyste se k ní vrátili, a na konci druhého argumentu přidejte
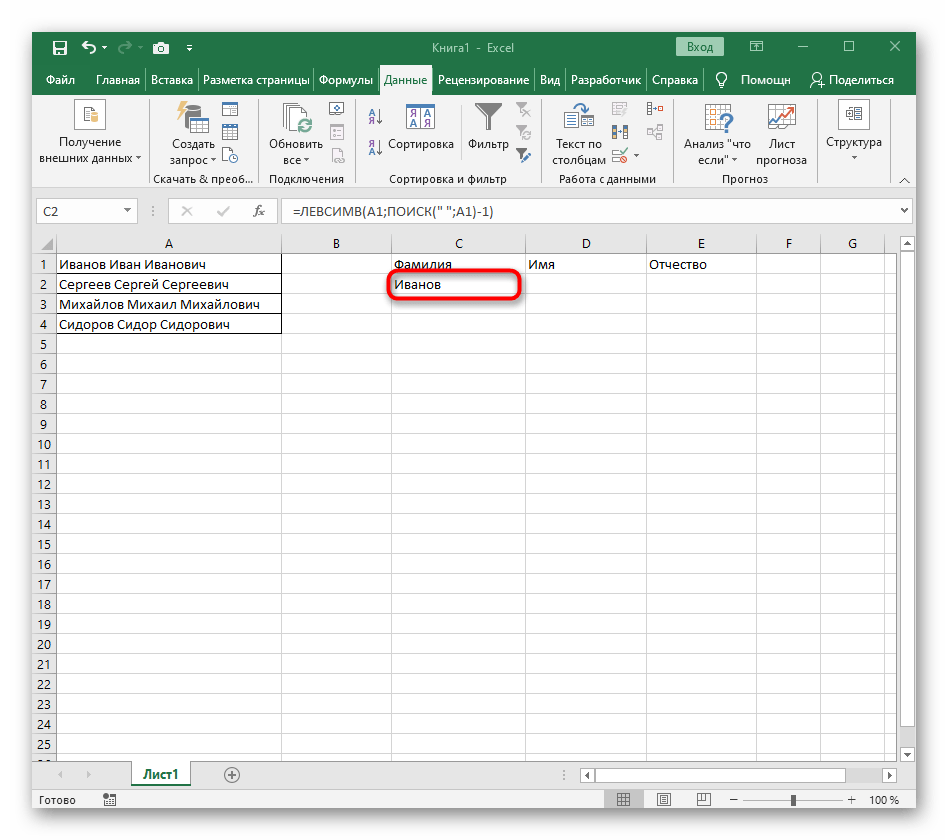
-1. To je nezbytné, aby vzorec "NAJÍT" zohlednil ne hledanou mezeru, ale znak před ní.Jak je vidět na následujícím snímku obrazovky, výstupem je příjmení bez jakýchkoli mezer, což znamená, že sestavení vzorců bylo provedeno správně. - Zavřete editor funkcí a ujistěte se, že slovo se správně zobrazuje v nové buňce.
- Držte buňku v pravém dolním rohu a přetáhněte ji dolů na požadovaný počet řádků, abyste ji roztáhli. Tak se dosadí hodnoty dalších výrazů, které je třeba rozdělit, a provedení vzorce probíhá automaticky.
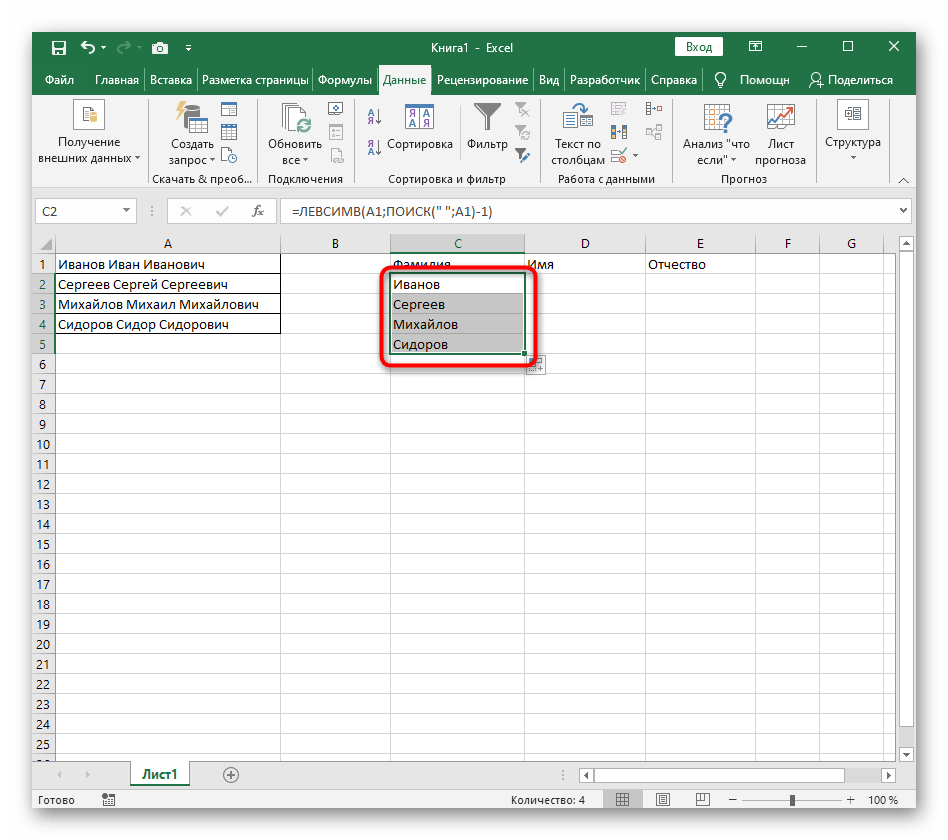
Úplně vytvořený vzorec má tvar =LEVÝ(A1;HLEDAT(" ";A1)-1), můžete jej vytvořit podle výše uvedeného návodu nebo vložit tento, pokud podmínky a oddělovač vyhovují. Nezapomeňte nahradit zpracovávanou buňku.
Krok 2: Rozdělení druhého slova
Nejtěžší je rozdělit druhé slovo, kterým je v našem případě jméno. Je to způsobeno tím, že je obklopeno mezerami z obou stran, takže je třeba je obě zohlednit při vytváření rozsáhlého vzorce pro správný výpočet pozice.
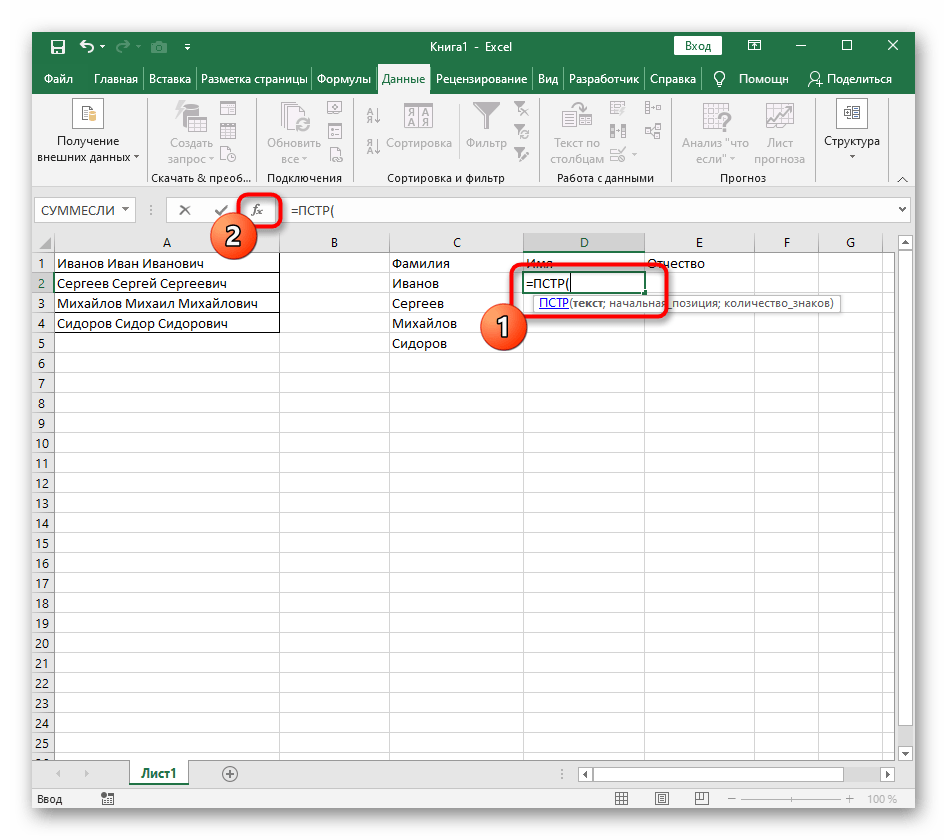
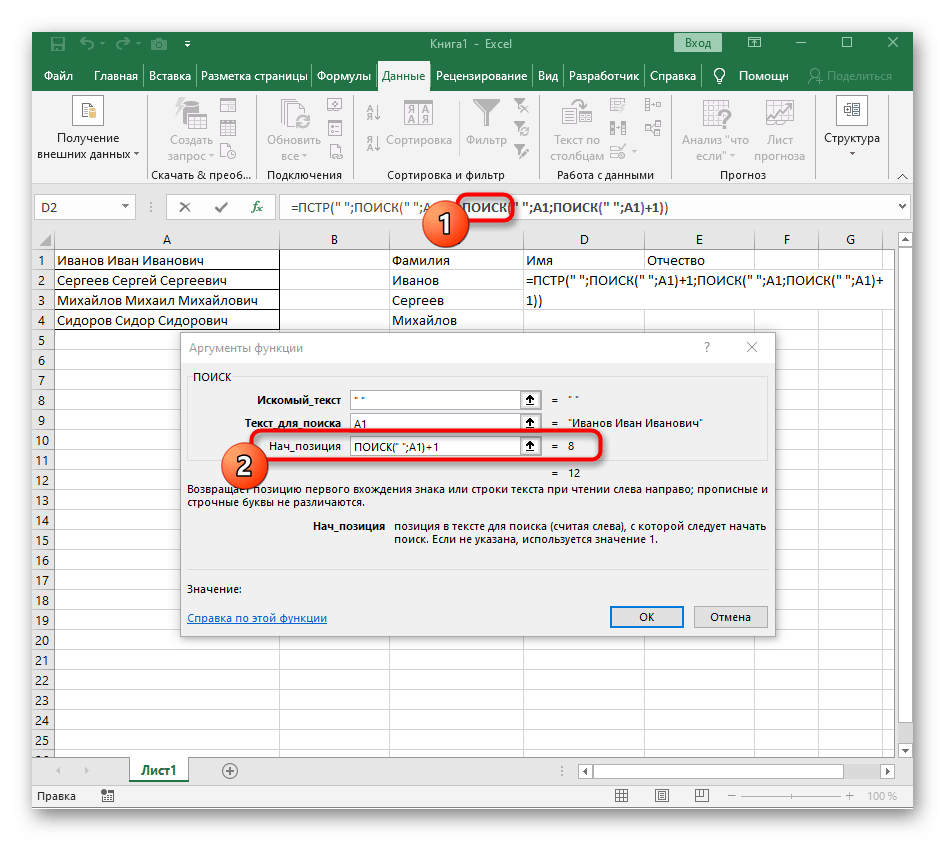
- V tomto případě se hlavním vzorcem stane
=MID(— zapište ji tímto způsobem a poté přejděte k oknu nastavení argumentů. - Tento vzorec bude hledat požadovaný řádek v textu, přičemž jako text vybíráme buňku s nápisem k rozdělení.
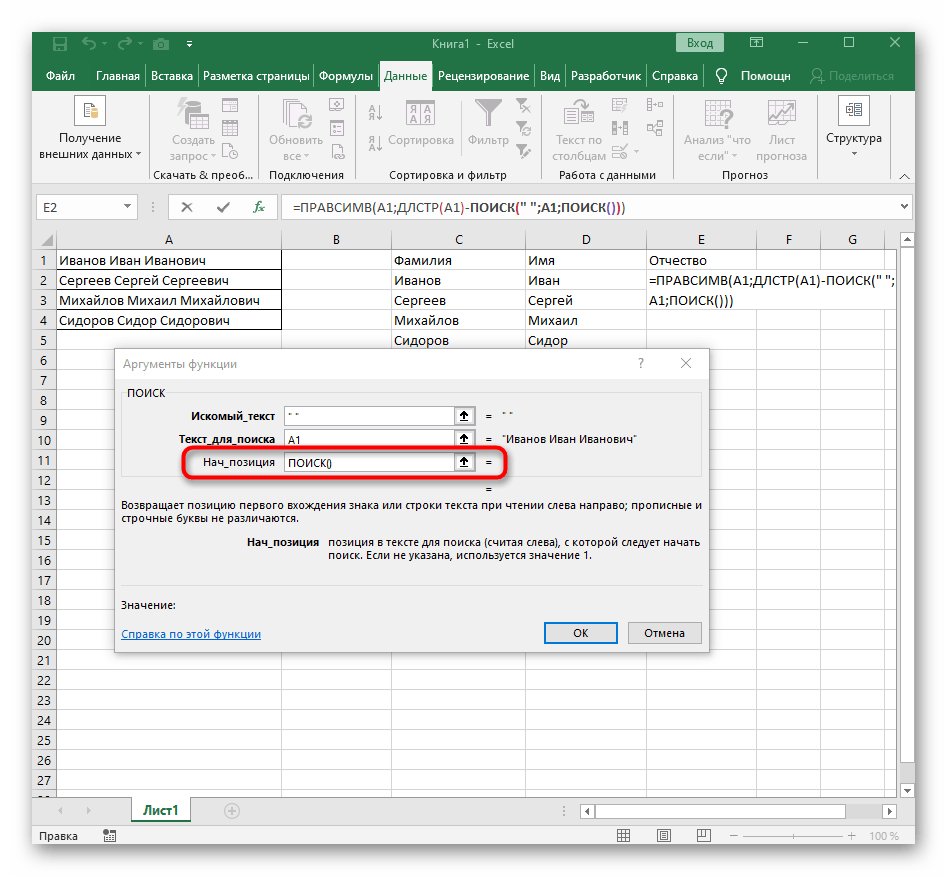
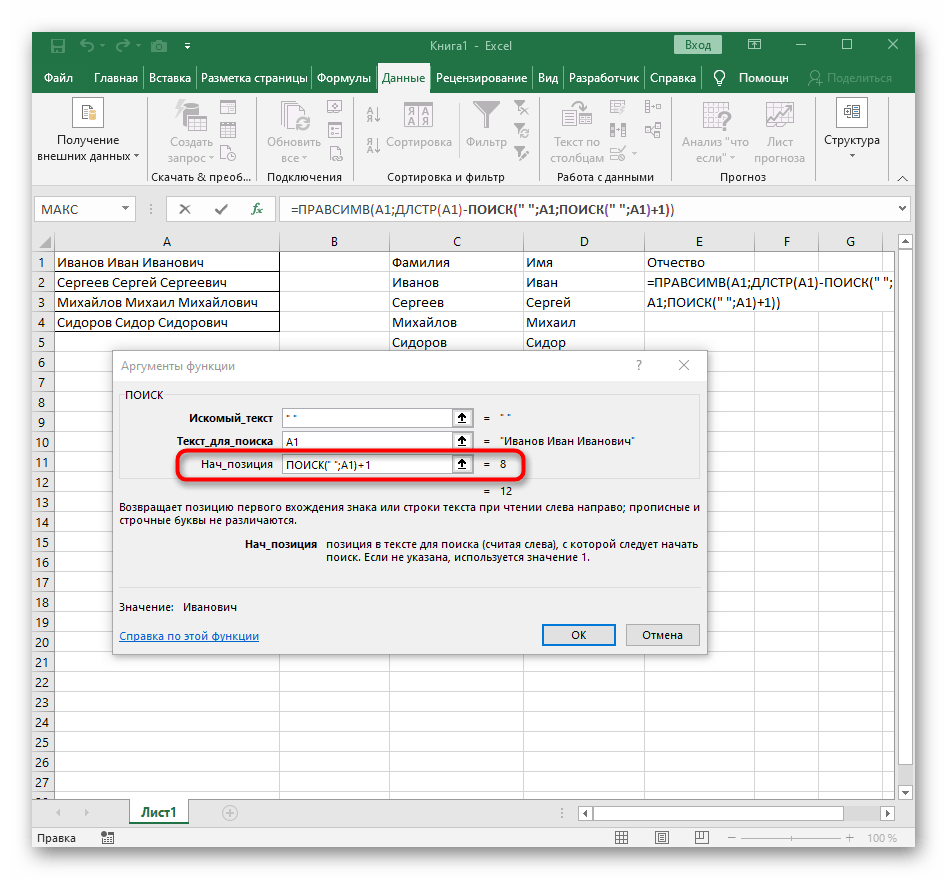
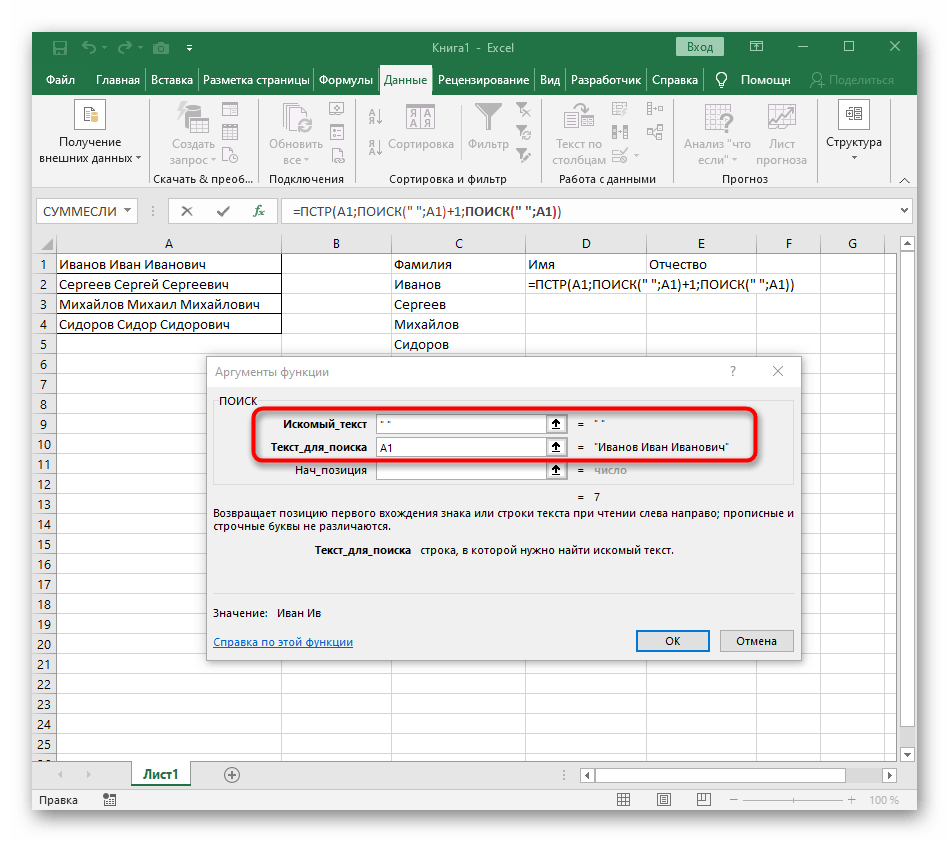
- Počáteční pozici řádku bude třeba určit pomocí již známého pomocného vzorce
HLEDAT(). - Jakmile ji vytvoříte a přejdete k ní, vyplňte ji přesně tak, jak bylo ukázáno v předchozím kroku.Jako hledaný text použijte oddělovač a buňku uveďte jako text pro hledání.
- Vraťte se k předchozímu vzorci, kde přidejte k funkci "NAJÍT"
+1na konci, aby se počítání začalo od následujícího znaku po nalezené mezeře. - Nyní vzorec již může začít hledat řetězec od prvního znaku jména, ale zatím ještě neví, kde ho ukončit, proto do pole "Počet_znaků" znovu zapište vzorec
NAJÍT(). - Přejděte k jejím argumentům a vyplňte je již známým způsobem.
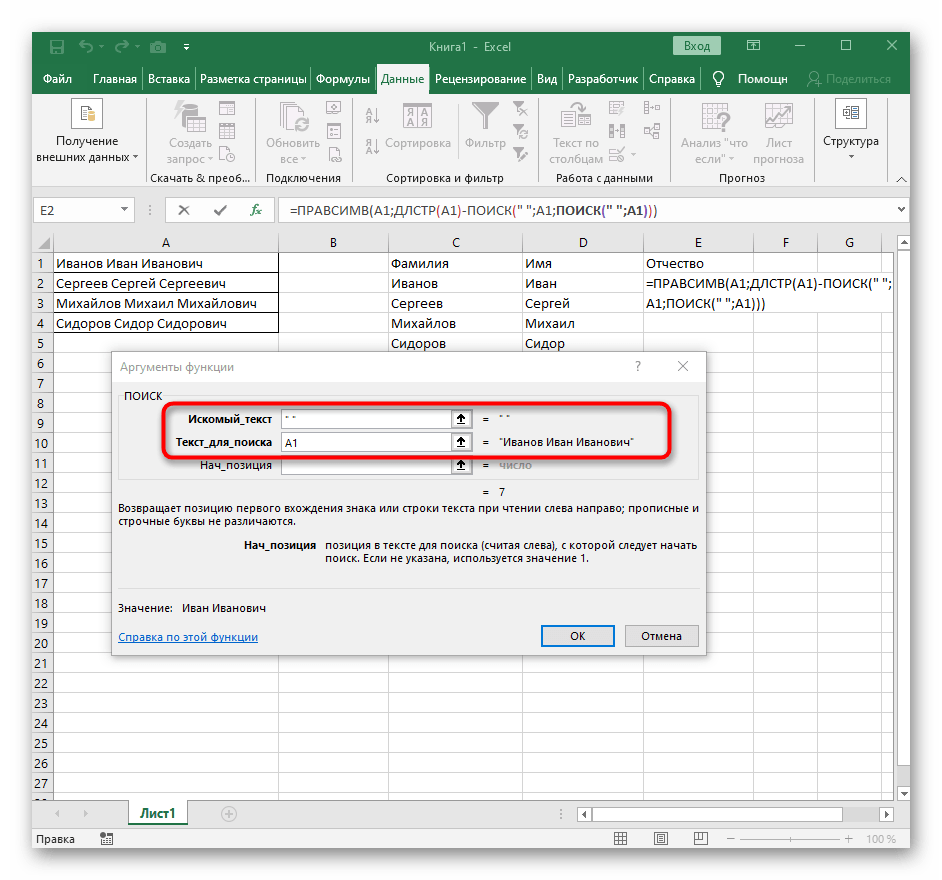
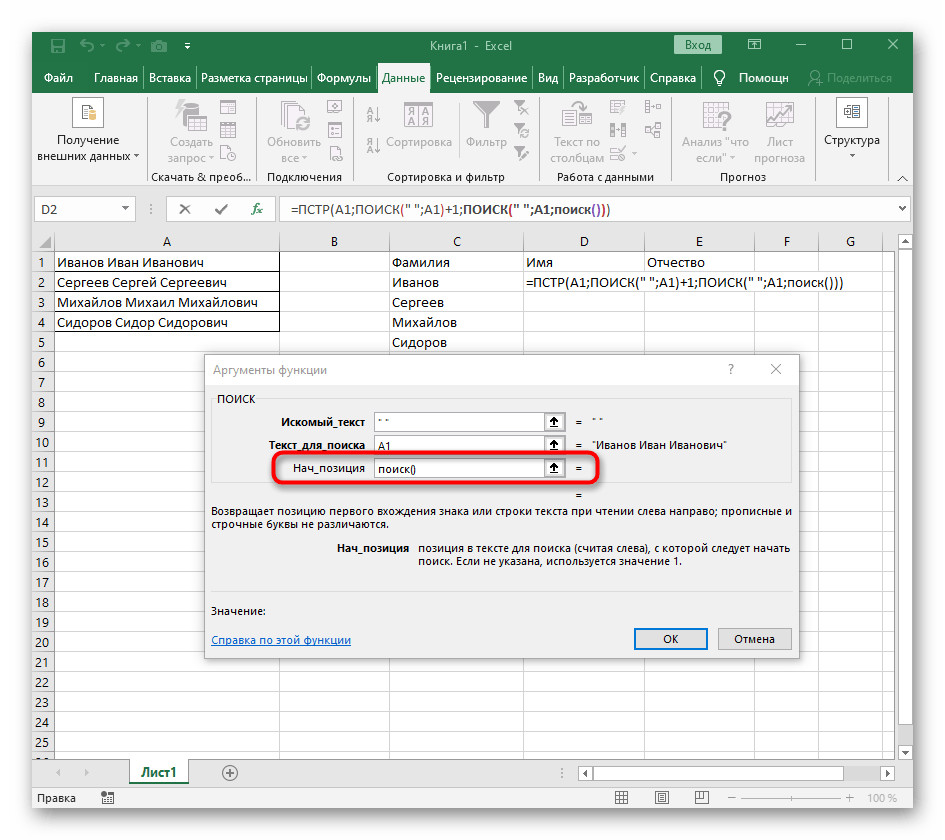
- Dříve jsme nezvažovali počáteční pozici této funkce, ale nyní je třeba tam také zapsat
NAJÍT(), protože tento vzorec by měl najít nikoli první mezeru, ale druhou. - Přejděte k vytvořené funkci a vyplňte ji stejným způsobem.
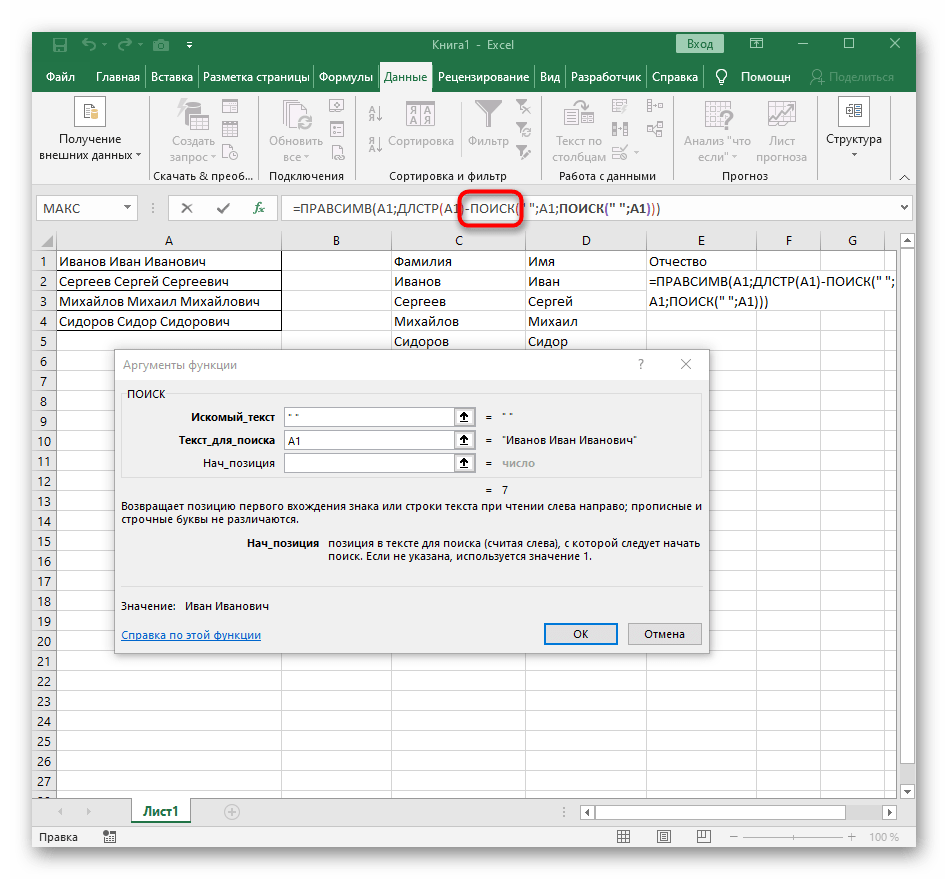
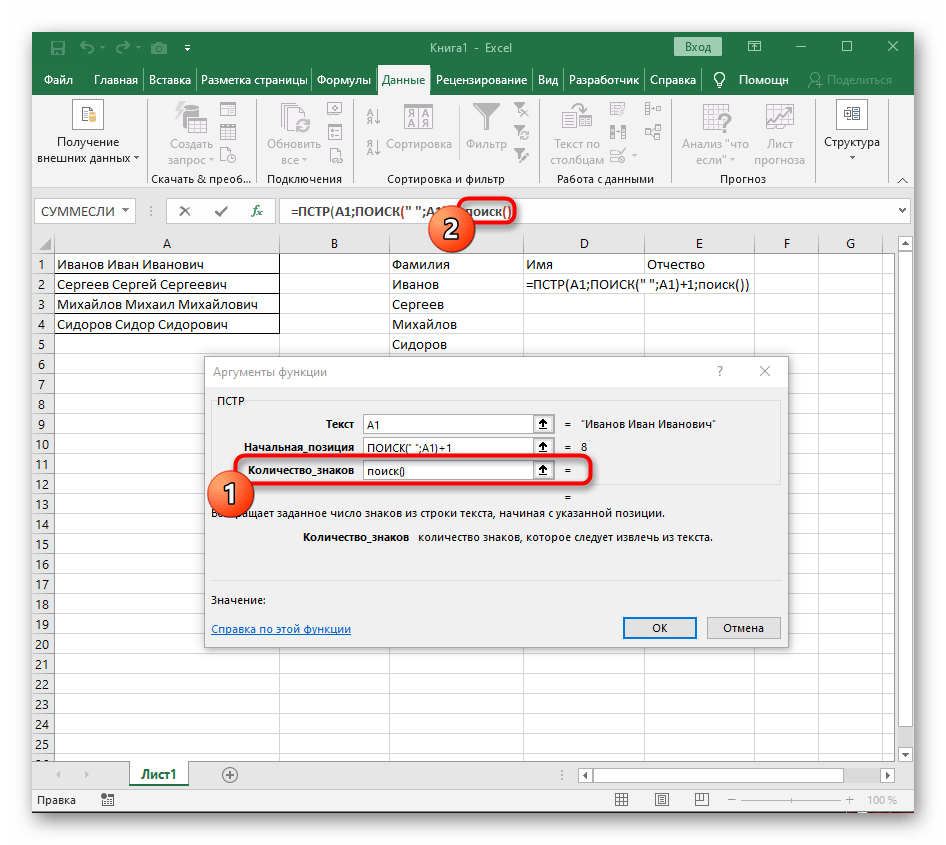
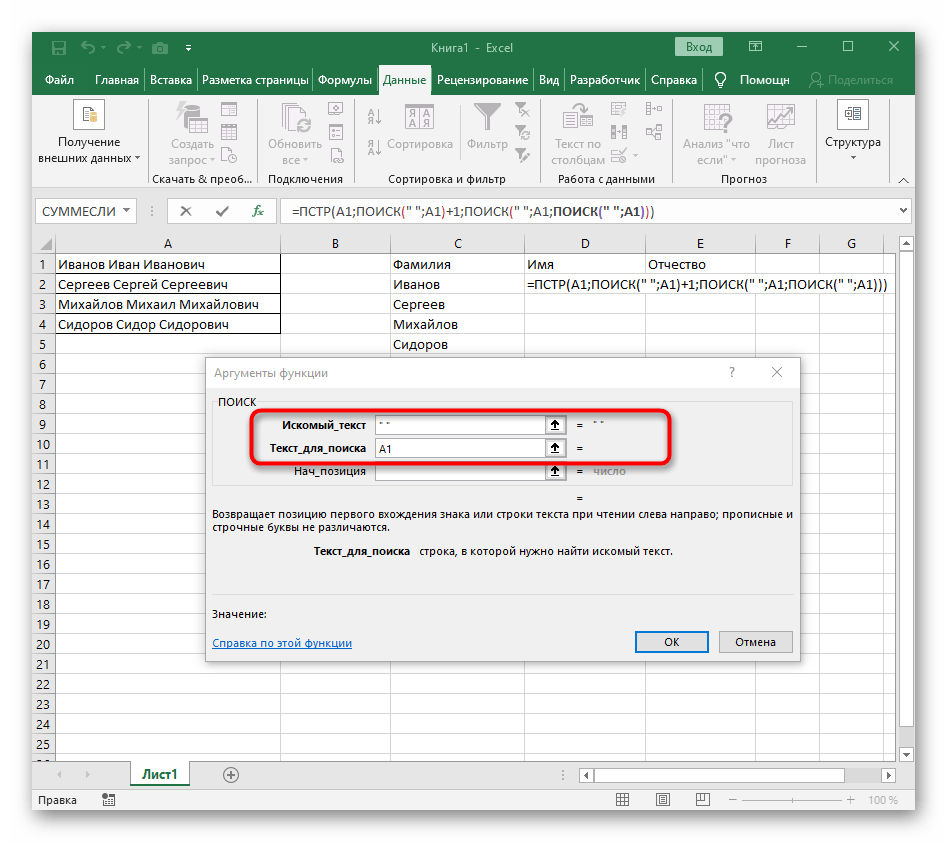
- Vraťte se k prvnímu
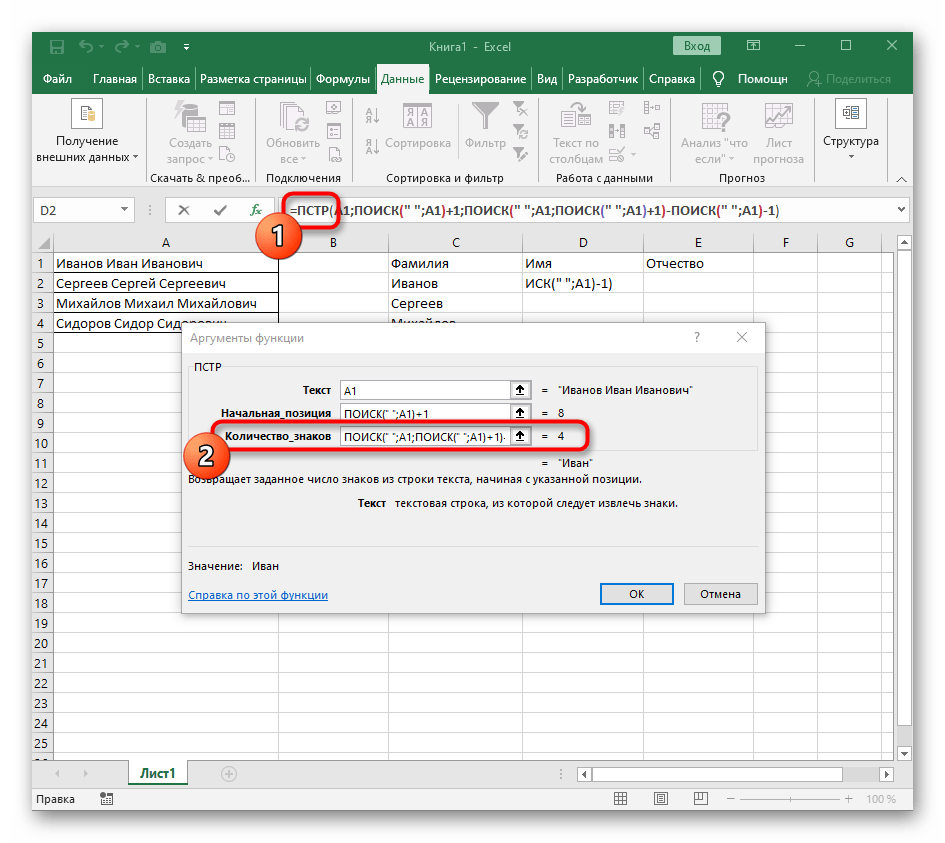
"NAJÍT"a doplňte do "Počáteční_pozice"+1na konci, protože pro hledání řetězce není potřeba mezera, ale následující znak. - Klikněte na kořen
=ČÁSTa umístěte kurzor na konec řetězce "Počet_znaků". - Doplňte tam výraz
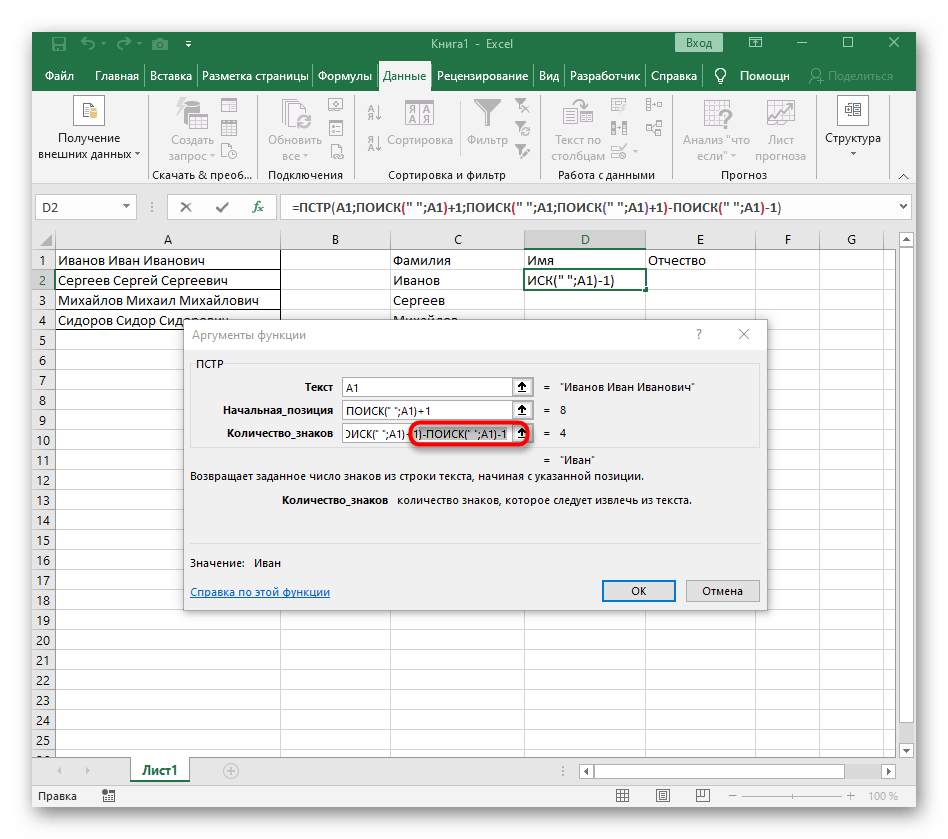
-NAJÍT(" ";A1)-1)pro dokončení výpočtů mezer. - Vraťte se k tabulce, rozšiřte vzorec a ujistěte se, že se slova zobrazují správně.
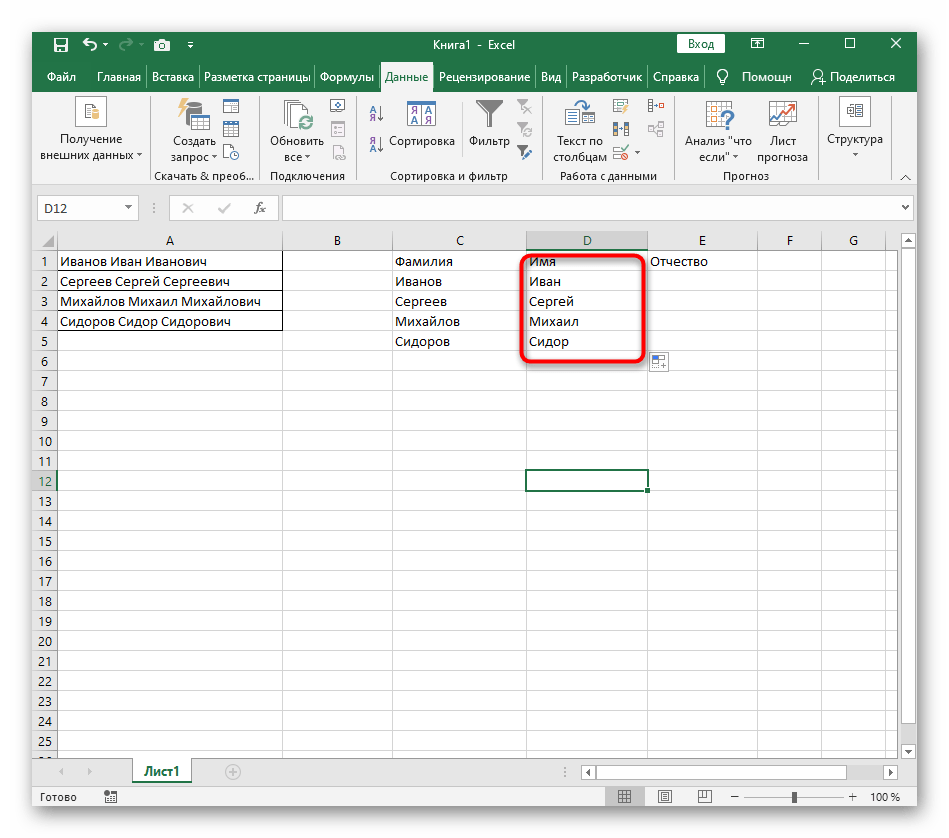
Vzorec se ukázal být velký a ne všichni uživatelé chápou, jak přesně funguje. Jde o to, že pro hledání řetězce bylo nutné použít hned několik funkcí, které určují počáteční a koncové pozice mezer, a poté se od nich odečítal jeden znak, aby tyto mezery nebyly zobrazeny.Nakonec je vzorec následující: =MID(A1;FIND(" ";A1)+1;FIND(" ";A1;FIND(" ";A1)+1)-FIND(" ";A1)-1). Použijte ho jako příklad, nahraďte číslo buňky s textem.
Krok 3: Rozdělení třetího slova
Poslední krok našeho návodu zahrnuje rozdělení třetího slova, což vypadá podobně jako u prvního, ale celkový vzorec se mírně mění.
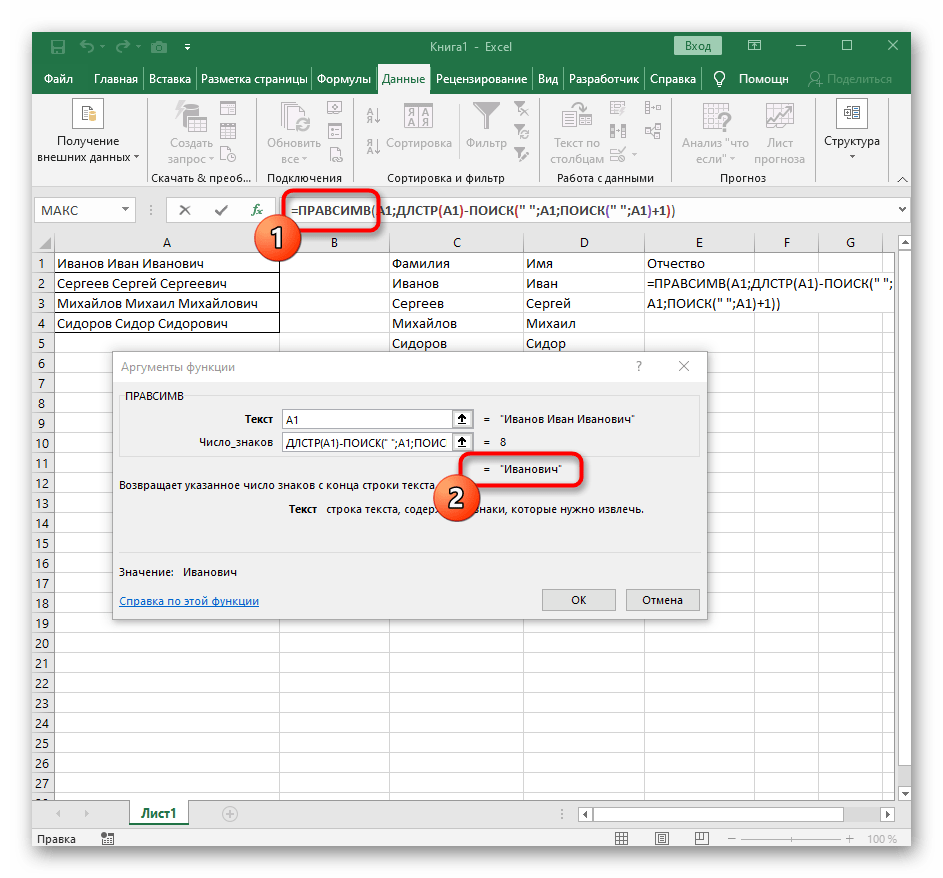
- Do prázdné buňky pro umístění budoucího textu napište
=RIGHT(a přejděte k argumentům této funkce. - Jako text uveďte buňku s nápisem pro rozdělení.
- Tentokrát pomocná funkce pro hledání slova se nazývá
LEN(A1), kde A1 — stejná buňka s textem. Tato funkce určuje počet znaků v textu, a my se zaměříme pouze na vhodné. - K tomu přidejte
-FIND()a přejděte k úpravě tohoto vzorce. - Zadejte již známou strukturu pro hledání prvního oddělovače v řetězci.
- Přidejte pro počáteční pozici ještě jeden
FIND(). - Ukažte mu stejnou strukturu.
- Vraťte se k předchozímu vzorci "FIND".
- Přidejte pro jeho počáteční pozici
+1. - Přejděte k jádru vzorce
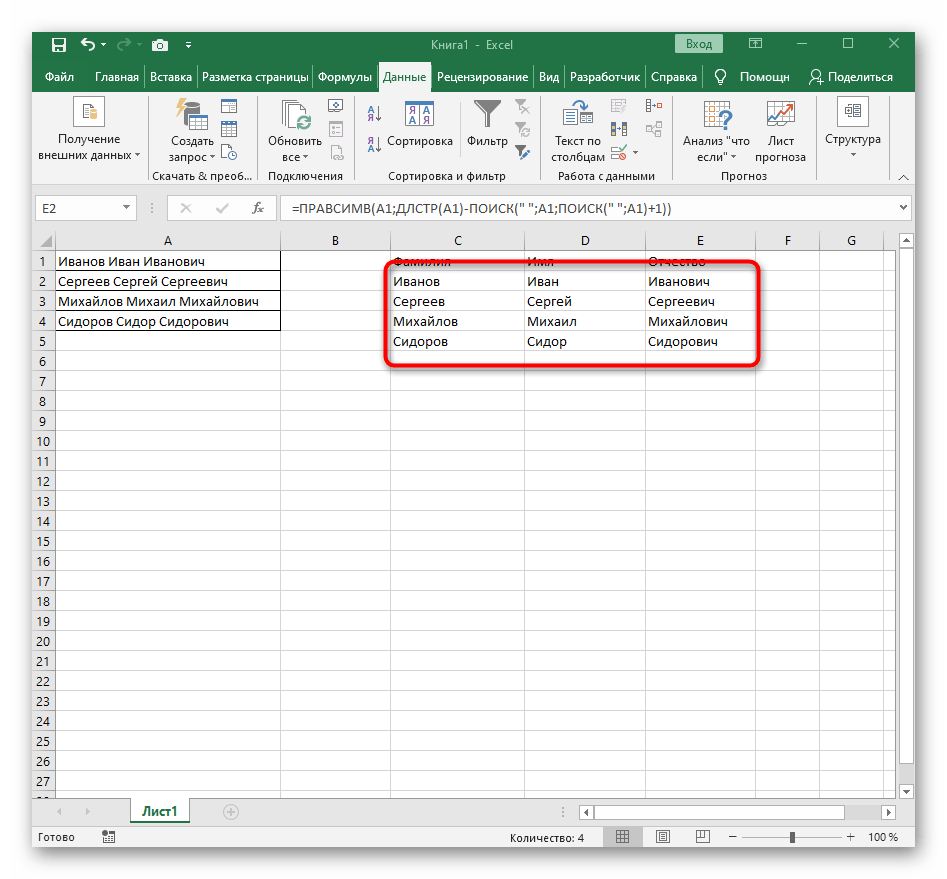
RIGHTa ujistěte se, že výsledek se zobrazuje správně, a teprve poté potvrďte provedené změny. Celkový vzorec v tomto případě vypadá jako=RIGHT(A1;LEN(A1)-FIND(" ";A1;FIND(" ";A1)+1)). - Nakonec na následujícím snímku obrazovky vidíte, že všechna tři slova jsou správně rozdělena a nacházejí se ve svých sloupcích. K tomu bylo nutné použít různé vzorce a pomocné funkce, ale to umožňuje dynamicky rozšiřovat tabulku a nemusíte se obávat, že byste museli text znovu rozdělovat. V případě potřeby jednoduše rozšiřujte vzorec jeho posunutím dolů, aby se další buňky automaticky zahrnuly.