Metody pro porovnávání tabulek v aplikaci Microsoft Excel
Poměrně často uživatelé aplikace Excel mají za úkol porovnat dvě tabulky nebo seznamy, aby identifikovali rozdíly nebo chybějící prvky v nich. Každý uživatel se s tímto úkolem vyrovnává svým vlastním způsobem, ale častěji se na řešení tohoto problému věnuje značné množství času, protože ne všechny přístupy k tomuto problému jsou racionální. Současně existuje několik validovaných algoritmů akce, které vám umožní porovnat seznamy nebo tabulkové sestavy v poměrně krátké době s minimálním úsilím. Podívejme se blíže na tyto možnosti.
Čtěte také: Srovnání dvou dokumentů v MS Word
Obsah
Metody srovnání
Existuje poměrně málo způsobů, jak porovnat tabulkové oblasti v aplikaci Excel, ale lze je rozdělit do tří velkých skupin:
Na základě této klasifikace je na prvním místě vybrána metoda porovnání a určena je i specifická akce a algoritmy pro provedení úkolu. Například při porovnávání v různých knihách musíte současně otevřít dva soubory aplikace Excel.
Dále je třeba říci, že porovnávání tabulek má smysl pouze tehdy, když mají podobnou strukturu.
Metoda 1: Jednoduchý vzorec
Nejjednodušší způsob, jak porovnávat data ve dvou tabulkách, je použít jednoduchý vzorec rovnosti. Pokud se data shodují, udává TRUE indikátor, a pokud ne, pak - FALSE. Můžete porovnat jak číselná data, tak text. Nevýhodou této metody je, že může být použita pouze tehdy, jsou-li údaje v tabulce seřazeny nebo seřazeny shodně, synchronizovány a mají stejný počet řádků. Podívejme se, jak tuto metodu použít v praxi pomocí příkladu dvou tabulek umístěných na jednom listu.
Takže máme dvě jednoduché tabulky se seznamy zaměstnanců podniku a jejich platy. Je třeba porovnat seznamy zaměstnanců a identifikovat nesrovnalosti mezi sloupci, ve kterých jsou umístěna jména.
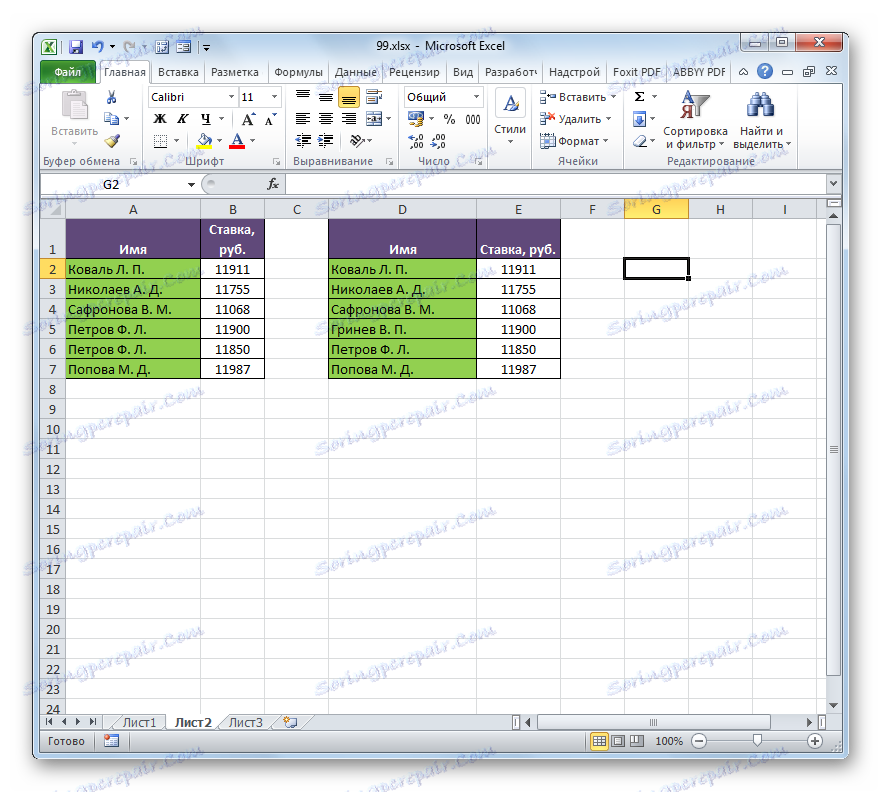
- K tomu potřebujeme další sloupec na listu. Zadejte znamení "=" tam. Poté klikněte na první jméno, které chcete porovnat v prvním seznamu. Opět vložte symbol "=" z klávesnice. Dále klikněte na první buňku sloupce, který porovnáváme ve druhé tabulce. Byl získán výraz následujícího typu:
=A2=D2![Vzorec pro porovnávání buněk v aplikaci Microsoft Excel]()
Ačkoliv se samozřejmě v každém konkrétním případě budou souřadnice lišit, podstata zůstane stejná.
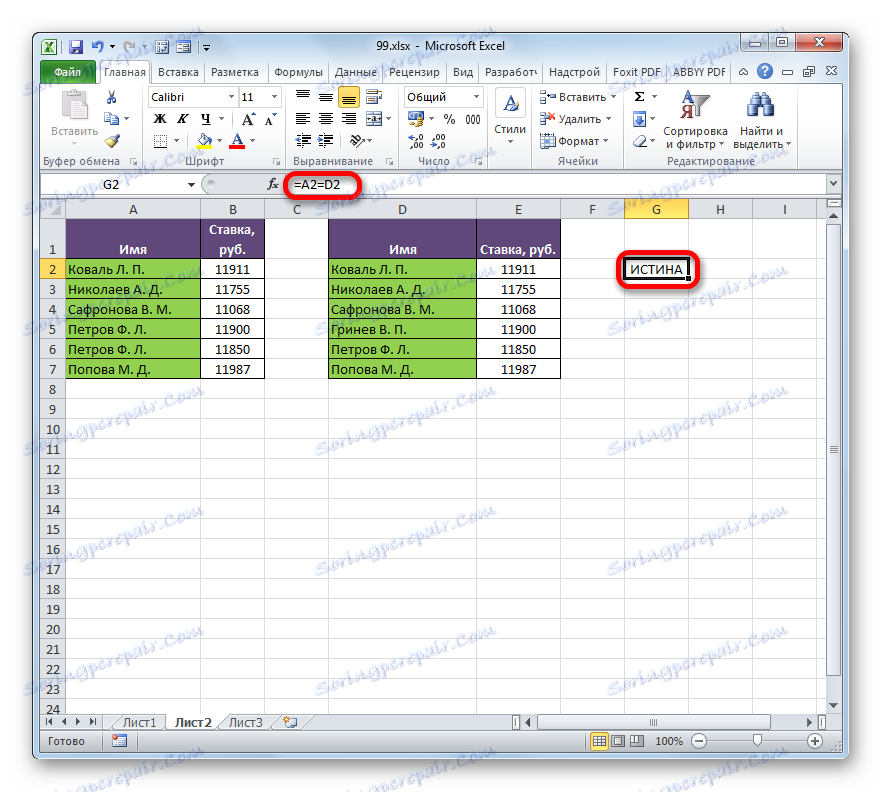
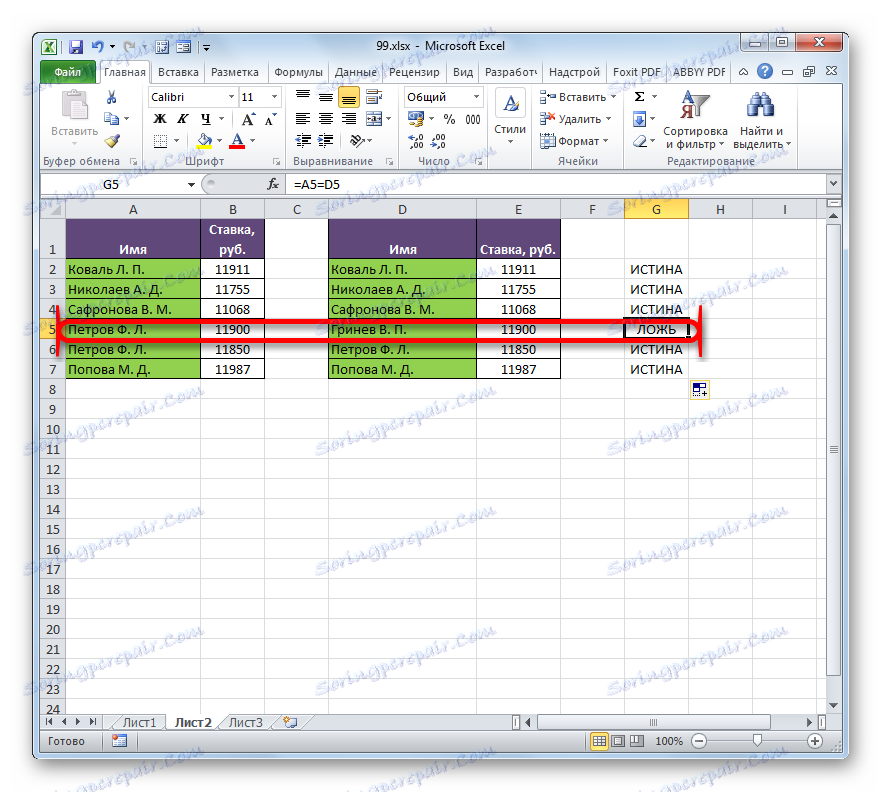
- Klepnutím na tlačítko Enter získáte výsledky porovnání. Jak je vidět, při porovnávání prvních buněk obou seznamů indikoval program indikátor "TRUE" , což znamená, že se data shodují.
- Teď musíme provést podobnou operaci se zbývajícími buňkami obou tabulek ve sloupcích, které srovnáváme. Ale můžete pouze zkopírovat vzorec, který ušetří spoustu času. Zvláště tento faktor je důležitý při porovnávání seznamů s velkým počtem řádků.
Nejjednodušší způsob, jak provést kopírování, je použití rukojeti výplně. Přesuňme kurzor do pravého dolního rohu buňky, kde máme ukazatel TRUE . V tomto případě je třeba jej převést na černý kříž. Toto je značka naplnění. Klepněte na levé tlačítko myši a přetáhněte kurzor směrem dolů počet řádků v porovnávaných tabulkových polích.
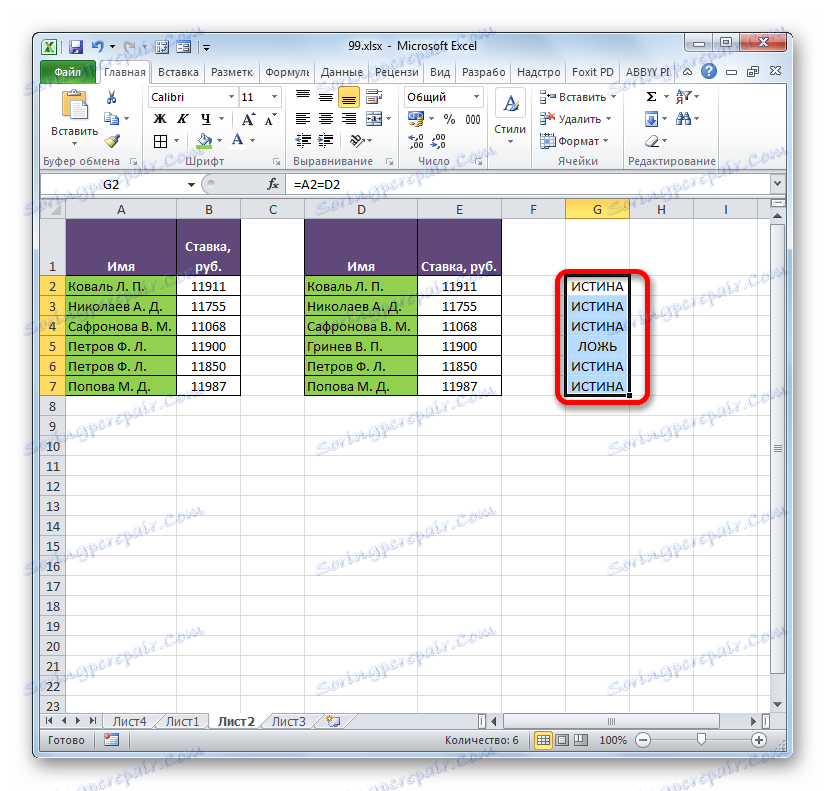
- Jak vidíte, nyní v dalším sloupci byly zobrazeny všechny výsledky porovnání dat ve dvou sloupcích tabulek. V našem případě data neodpovídala pouze jednomu řádku. Při jejich porovnávání vzorec získal výsledek "LIE" . Pro všechny ostatní řádky, jak vidíme, porovnávací vzorec byl vydán indikátorem "TRUE" .
- Navíc je možné vypočítat počet nesouladů pomocí speciálního vzorce. Chcete-li to provést, vyberte prvek listu, na kterém bude výstup. Potom klikněte na ikonu "Vložit funkci" .
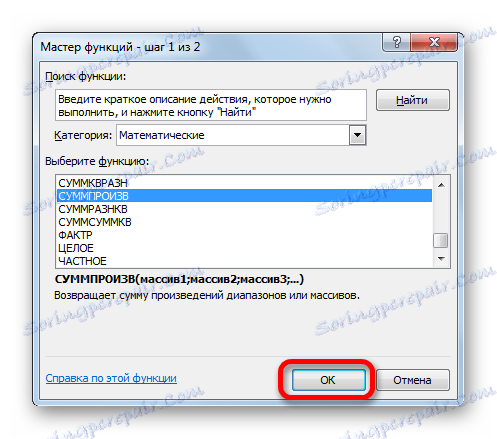
- V okně Průvodce funkcí , v okně "Matematická" skupina operátorů, vyberte název SUMPRODUCT . Klepněte na tlačítko "OK" .
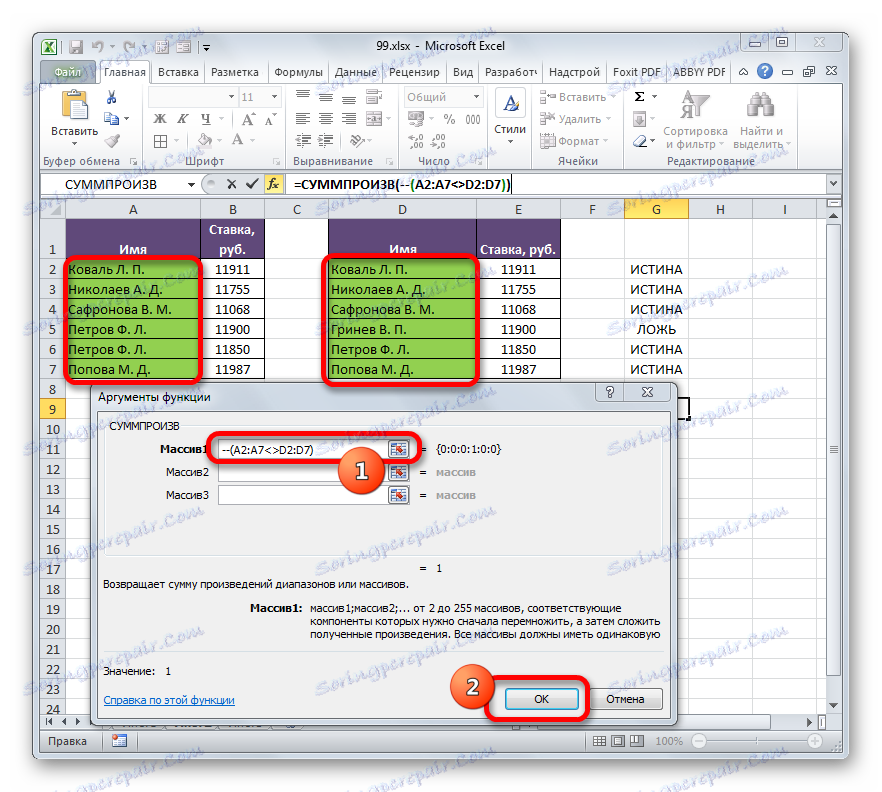
- Je aktivováno okno argumentu funkce SUMPRODUCT , jehož hlavním úkolem je vypočítat součet produktů vybraného rozsahu. Ale tato funkce může být použita pro naše účely. Syntaxe je poměrně jednoduchá:
=СУММПРОИЗВ(массив1;массив2;…)Celkově lze jako argumenty použít až 255 polí. Ale v našem případě použijeme pouze dvě pole, jako jeden argument.
Kurzor jsme umístili do pole "Array1" a v první oblasti vybrali srovnávaný rozsah dat. Poté vložte do pole značku "není rovno" ( <> ) a vyberte srovnávaný rozsah druhé oblasti. Pak obalte výsledný výraz s závorkami, před kterými položíme dva znaky "-" . V našem případě byl výraz:
--(A2:A7<>D2:D7)Klepněte na tlačítko "OK" .
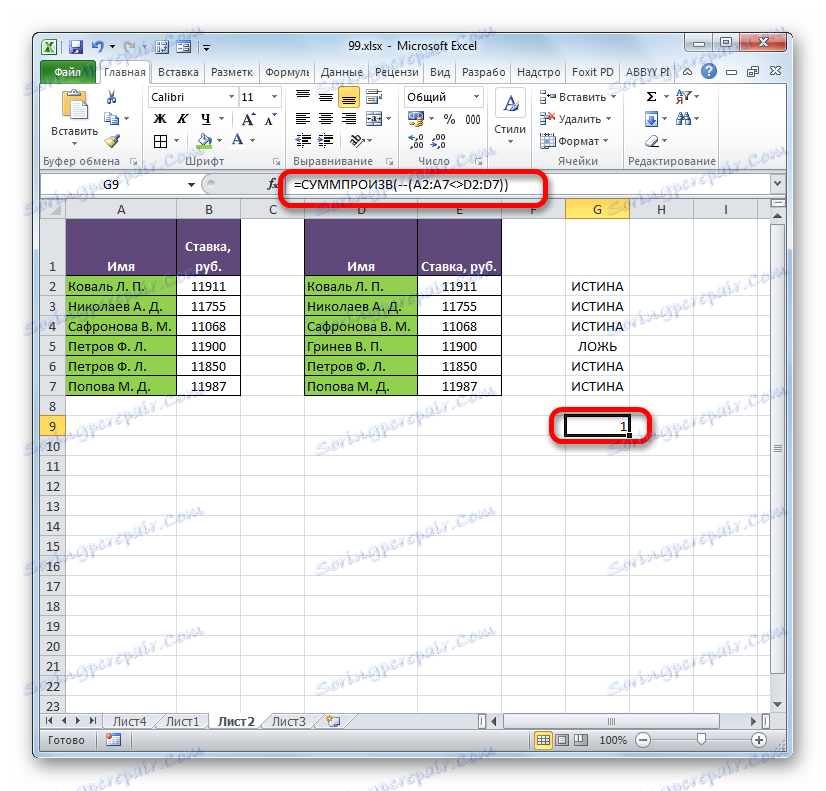
- Operátor vypočítá a zobrazí výsledek. Jak vidíte, v našem případě se výsledek rovná číslu "1" , to znamená, že v porovnávacích seznamech bylo nalezeno jedno nesoulad. Pokud by seznamy byly zcela totožné, výsledek by se rovnal počtu "0" .

Stejným způsobem můžete porovnávat data v tabulkách, které jsou na různých listech. V tomto případě je však žádoucí, aby čárky v nich byly očíslovány. V opačném případě je porovnávací postup téměř přesně stejný, jak je popsáno výše, s výjimkou skutečnosti, že při zadávání vzorce musíte přepínat mezi listy. V našem případě bude vypadat takto:
=B2=Лист2!B2
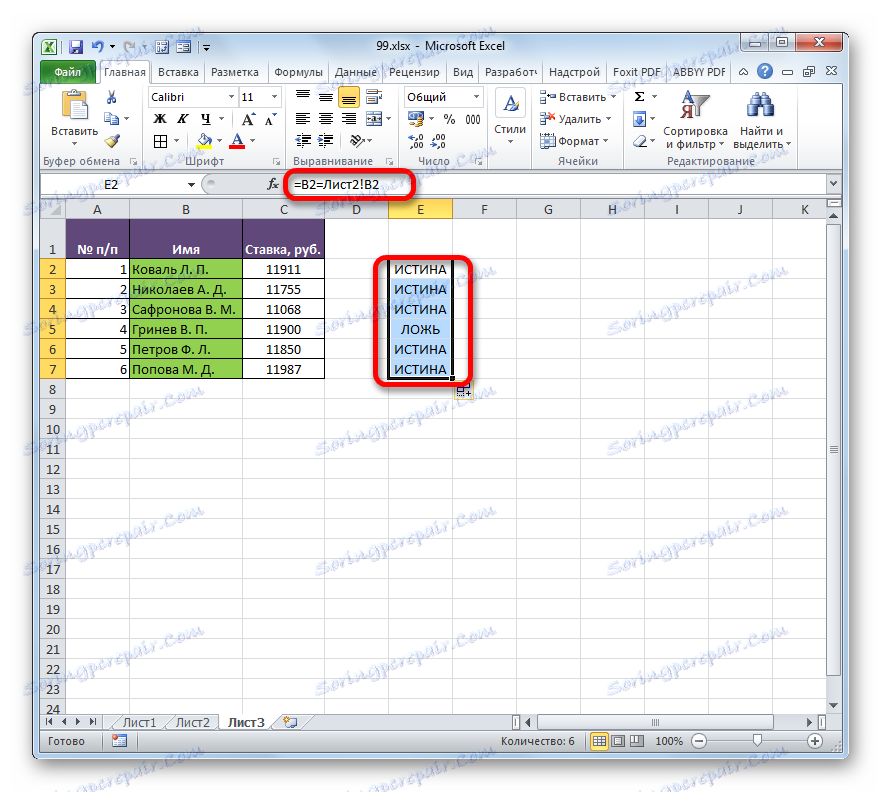
To znamená, jak vidíte, před datovými souřadnicemi, které se nacházejí na jiných listech, odlišné od místa, kde je zobrazen výsledek porovnání, jsou označeny číslo listu a vykřičník.
Metoda 2: Výběr skupin buněk
Pomocí nástroje pro výběr skupin buněk můžete provést srovnání. S ním můžete také porovnávat pouze synchronizované a objednané seznamy. Kromě toho by v tomto případě měly být seznamy umístěny vedle sebe na jednom listu.
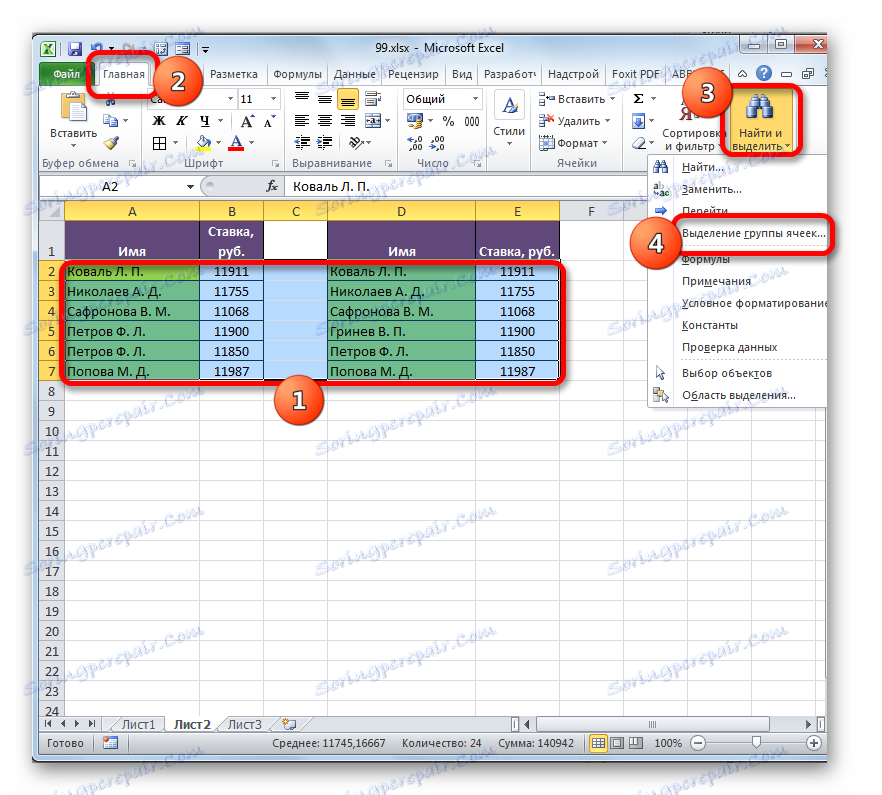
- Vybíráme porovnávané pole. Přejděte na kartu "Domov" . Potom klikněte na ikonu "Najít a vybrat " , která je umístěna na pásu karet v poli "Upravit" . Otevře se seznam, ve kterém vyberete položku "Výběr skupiny buněk ..." .
![Přejděte do okna výběru skupiny buněk v aplikaci Microsoft Excel]()
Kromě toho můžete také přistupovat k výběrovému okně pro skupinu buněk jiným způsobem. Tato volba bude užitečná zejména pro ty uživatele, kteří mají verzi programu dříve než aplikace Excel 2007, protože tyto metody nepodporují použití tlačítka "Najít a zvýraznit" . Vyberte pole, která chceme porovnat, a stiskněte klávesu F5 .
- Je aktivováno malé přechodové okno. Klepněte na tlačítko "Vybrat ..." v levém dolním rohu.
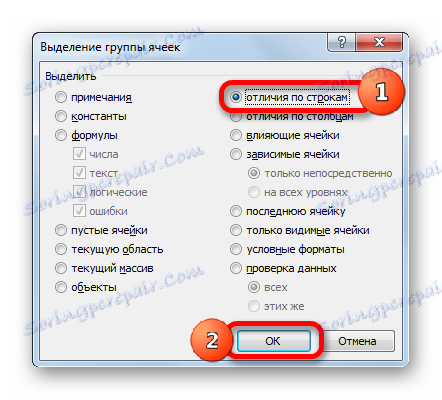
- Poté, podle libovolné z výše uvedených možností, spustí se okno pro výběr skupin buněk. Nastavte přepínač na pozici "Vybrat podle řádků" . Klikněte na tlačítko "OK" .
- Jak můžete vidět, pak budou nesouladné hodnoty řádků zvýrazněny jiným odstínem. Kromě toho, jak lze posoudit z obsahu řádku vzoru, program provede jednu z buněk aktivních v označených nesourodých řádcích aktivní.
Metoda 3: podmíněné formátování
Můžete provést porovnání pomocí metody podmíněného formátování. Stejně jako v předchozí metodě, porovnávané oblasti musí být na stejném listu aplikace Excel a musí být vzájemně synchronizovány.
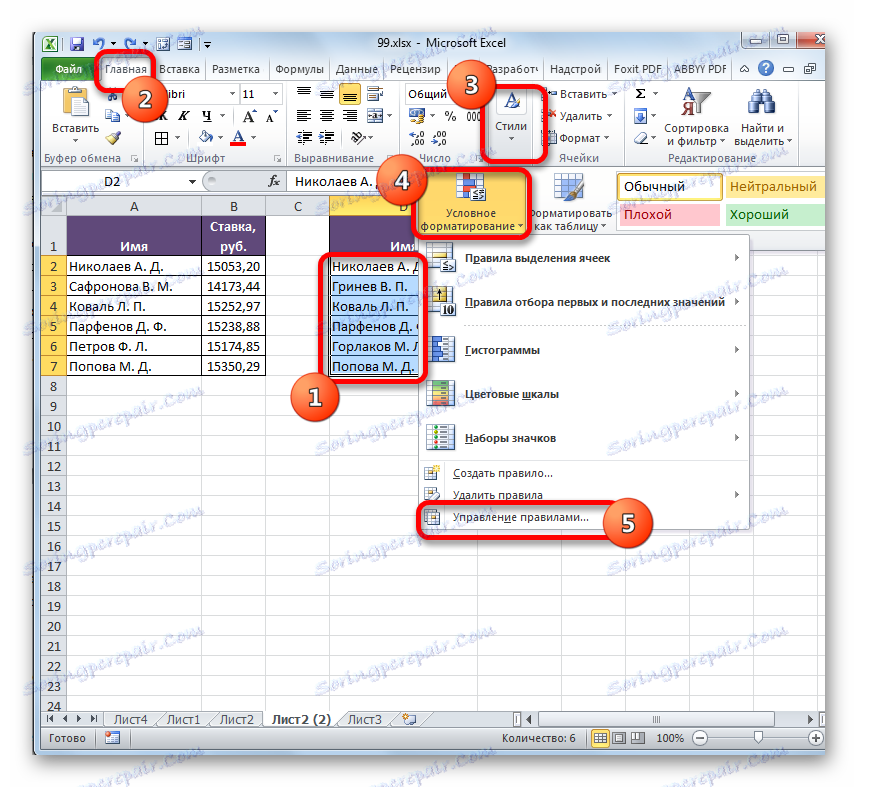
- Nejprve si vybereme, která oblast tabulky budeme považovat za hlavní a jak hledat rozdíly. Udělme to druhé v druhé tabulce. Proto vybereme seznam zaměstnanců, kteří jsou v něm. Po přesunu na kartu "Domov" klikneme na tlačítko "Podmíněné formátování" , které je umístěno na pásu v bloku "Styly" . V rozevíracím seznamu přejděte na položku Spravovat pravidla .
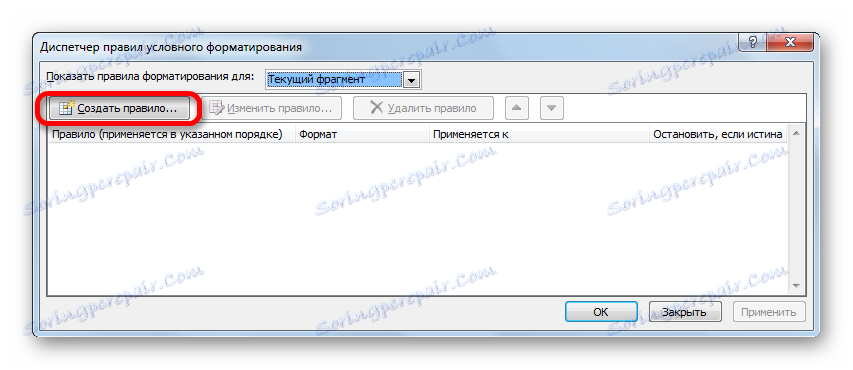
- Okno Správce pravidel je aktivováno. Klikněte na tlačítko Vytvořit pravidlo .
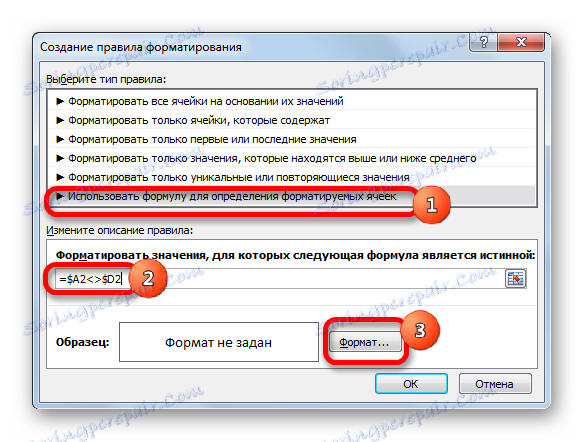
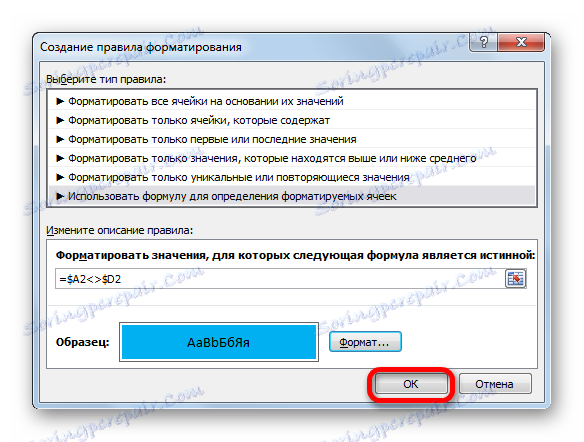
- V okně, které se otevře, vybereme položku "Použít vzorec" . V poli "Formát buňky" zapíšeme vzorec obsahující adresy prvních buněk v rozmezích porovnávaných sloupců, oddělených znakem "není rovno" ( <> ). Teprve před tímto výrazem bude znamení "=" . Navíc ke všem souřadnicím sloupců v tomto vzorci musíte použít absolutní adresování. Chcete-li to provést, vyberte vzorec pomocí kurzoru a třikrát stiskněte klávesu F4 . Jak můžete vidět, kolem všech sloupových adres bylo dolarové znamení, což znamená, že tyto vazby jsou absolutní. V našem konkrétním případě má vzorec následující formu:
=$A2<>$D2Tento výraz zapíšeme do výše uvedeného pole. Poté klikněte na tlačítko "Formát ..." .
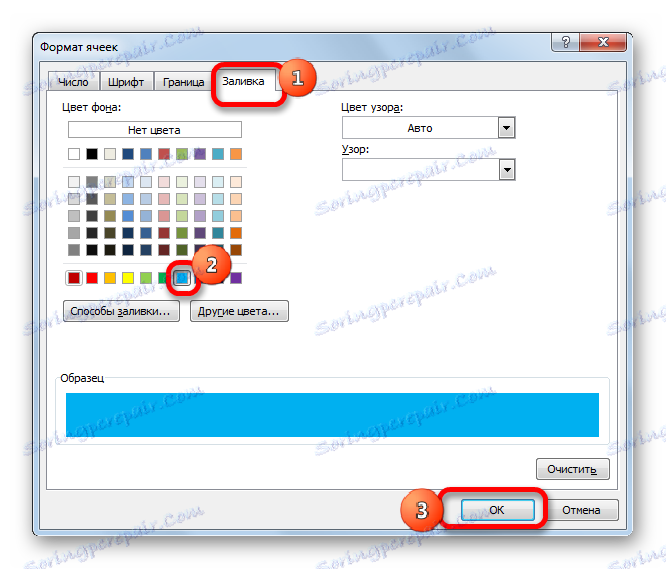
- Okno "Formát buňky" je aktivováno. Přejděte na záložku "Vyplnit" . Zde v seznamu barev zastavíme výběr na barvě, kterou chceme namalovat ty prvky, kde se data nebudou shodovat. Klikněte na tlačítko "OK" .
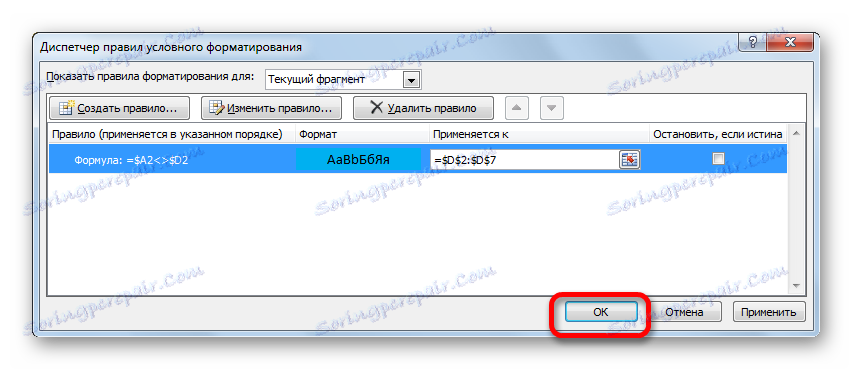
- Vraťte se do okna pro vytvoření pravidla pro formátování, klikněte na tlačítko "OK" .
- Po automatickém přesunu do okna "Správce pravidel" klikněte na tlačítko "OK" .
- Nyní ve druhé tabulce budou prvky, které mají data, která neodpovídají odpovídajícím hodnotám první plochy tabulky, zvýrazněna zvolenou barvou.
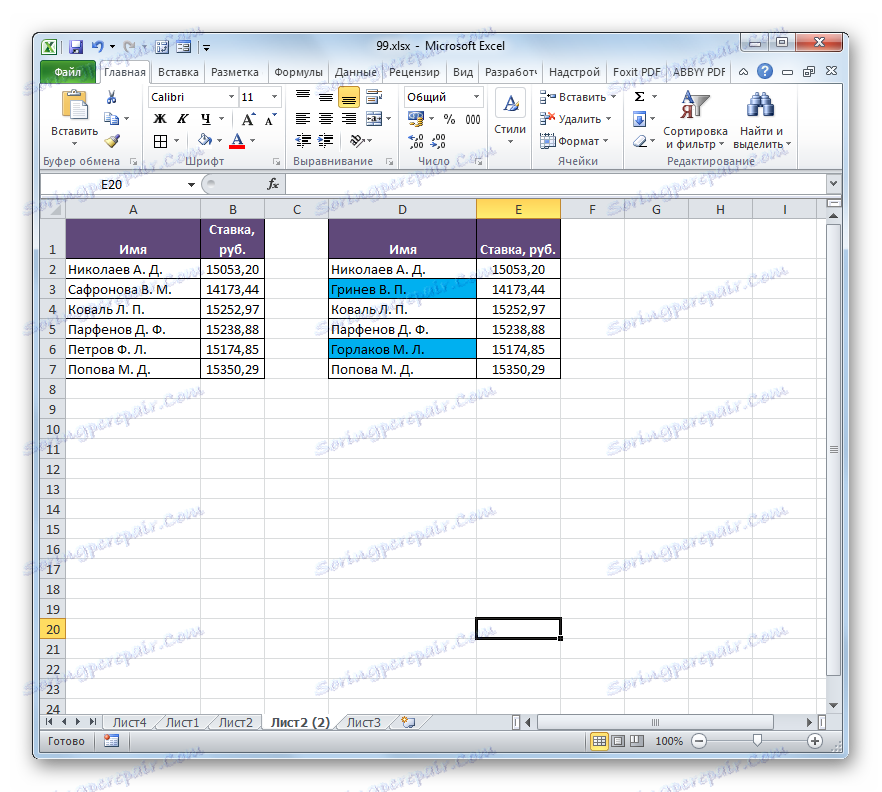
Existuje i jiný způsob, jak lze na úlohu použít podmíněné formátování. Stejně jako u předchozích verzí vyžaduje umístění obou srovnávaných oblastí na jednom listu, ale na rozdíl od dříve popsaných metod nebude podmínka synchronizace nebo třídění dat povinná, což rozlišuje tuto volbu od dříve popsaných.
- Vybíráme výběr oblastí, které je třeba porovnávat.
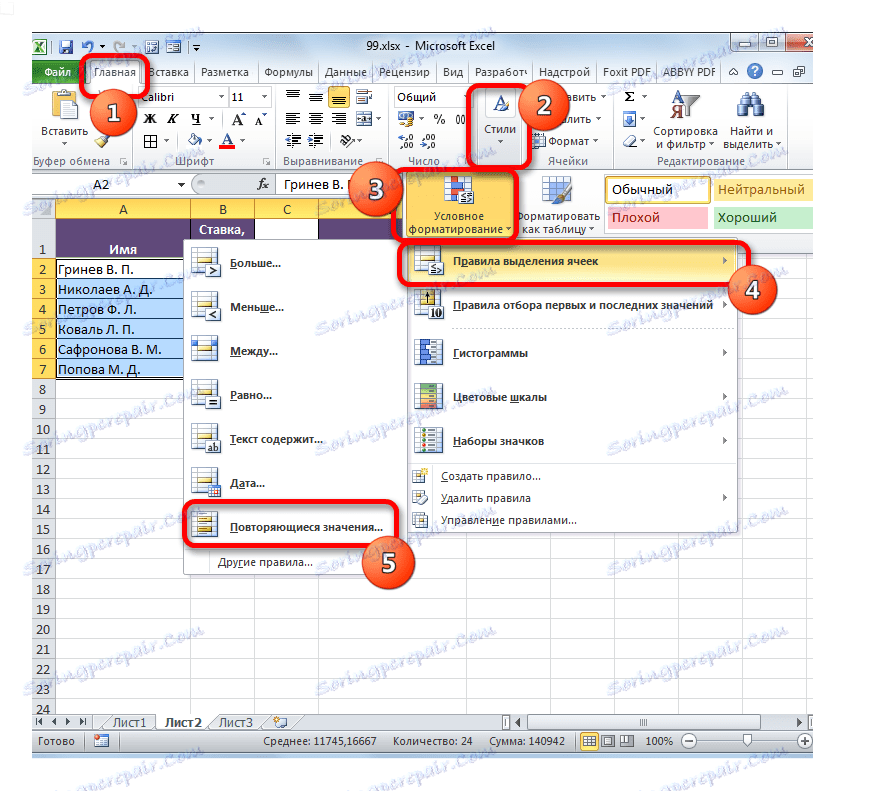
- Přejdeme na kartu s názvem "Domov" . Klepněte na tlačítko "Podmíněné formátování" . V aktivovaném seznamu vyberte položku "Pravidla výběru buňky" . V další nabídce si vyberete pozici "Duplicitní hodnoty" .
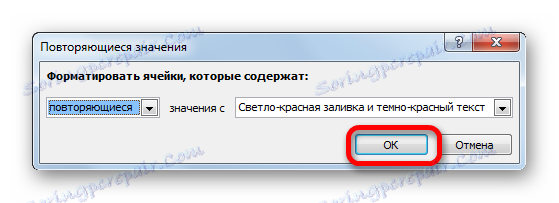
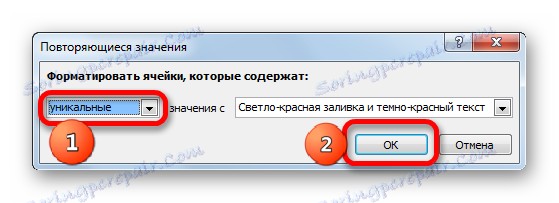
- Otevře se okno pro nastavení výběru duplicitních hodnot. Pokud jste vše udělali správně, pak v tomto okně zůstane pouze klepnutím na tlačítko "OK" . I když je to požadováno, můžete v odpovídajícím poli tohoto okna zvolit jinou barvu zvýraznění.
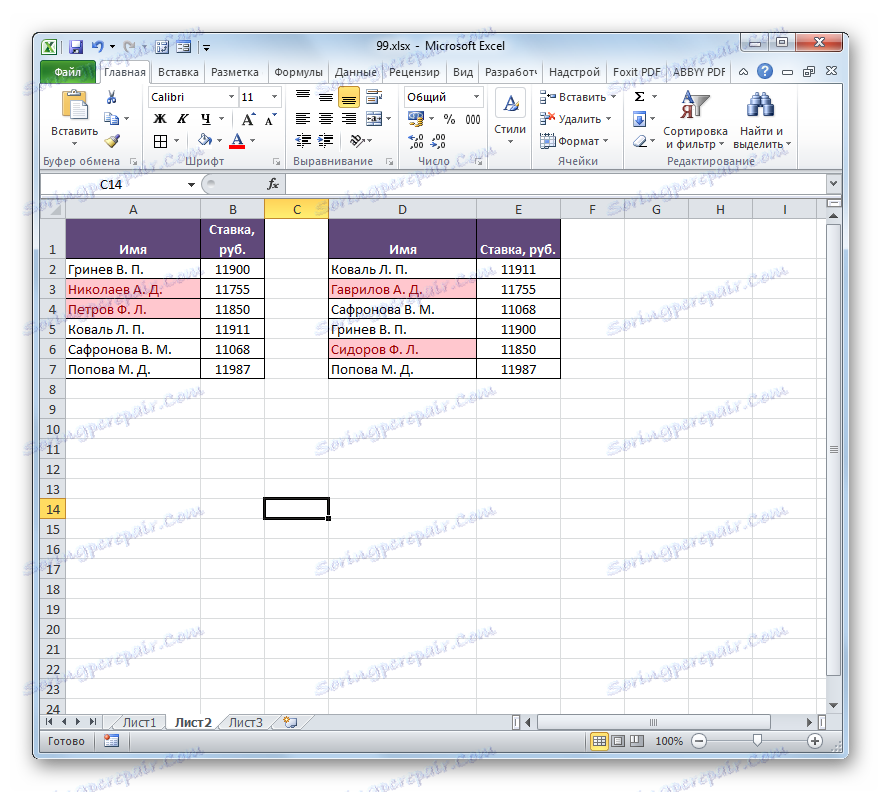
- Po provedení určité akce se všechny opakující se prvky zvýrazní vybranou barvou. Ty prvky, které neodpovídají, zůstanou zbarveny v původní barvě (výchozí je bílá). Takže můžete vizuálně vidět, jaký je rozdíl mezi poli.
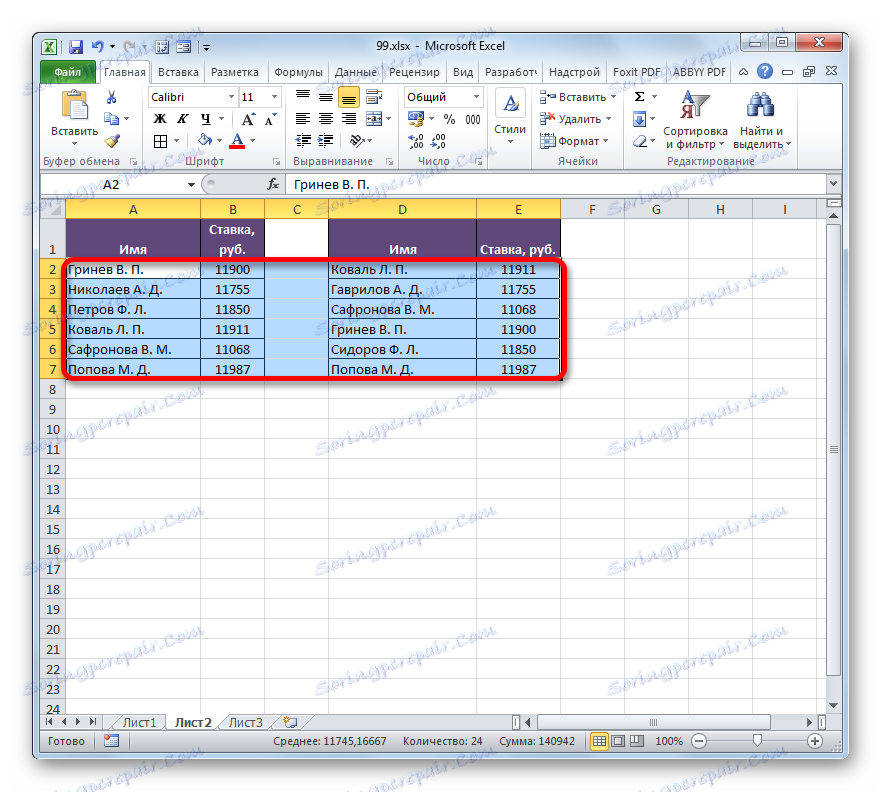
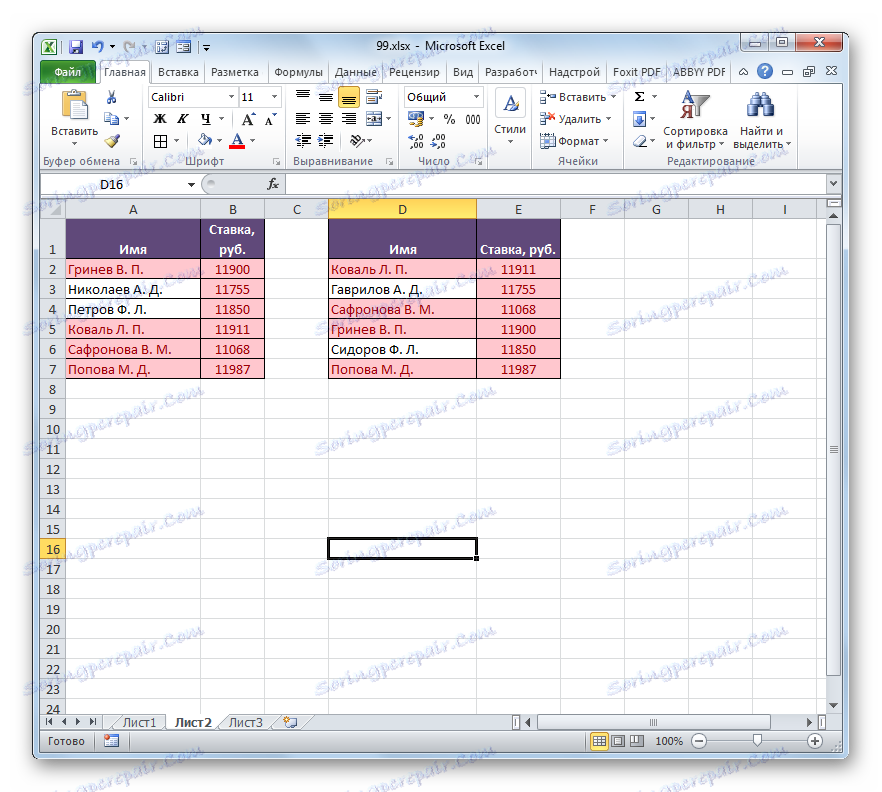
Pokud je to požadováno, naopak můžete namalovat nesouladné prvky a ty indikátory, které se shodují, opouštějí stejnou barvu. V tomto případě je algoritmus akcí téměř stejný, ale v okně nastavení pro výběr duplicitních hodnot v prvním poli namísto parametru "Duplikát" vyberte možnost "Jedinečný" . Poté klikněte na tlačítko "OK" .
Takto se zvýrazní ukazatele, které se neshodují.
Lekce: Podmíněné formátování v aplikaci Excel
Metoda 4: Složitý vzorec
Také můžete porovnávat data pomocí složitého vzorce založeného na funkci COUNTIF . Pomocí tohoto nástroje můžete počítat, kolik se každý prvok z vybraného sloupce druhé tabulky opakuje v prvním.
Operátor ZEMĚ odkazuje na statistickou skupinu funkcí. Jeho úkolem je počítat počet buněk, jejichž hodnoty splňují daný stav. Syntaxe tohoto operátora je:
=СЧЁТЕСЛИ(диапазон;критерий)
Argument "Rozsah" je adresa pole, ve kterém jsou vypočítané odpovídající hodnoty.
Argument kritéria nastavuje podmínku zápasu. V našem případě představují souřadnice specifických buněk oblasti první tabulky.
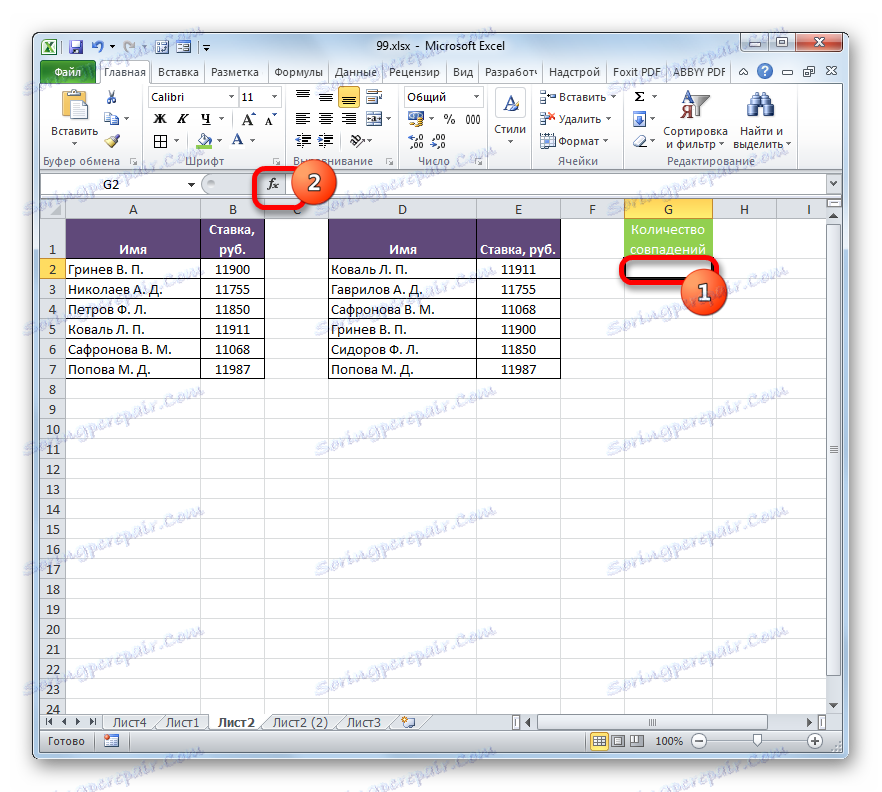
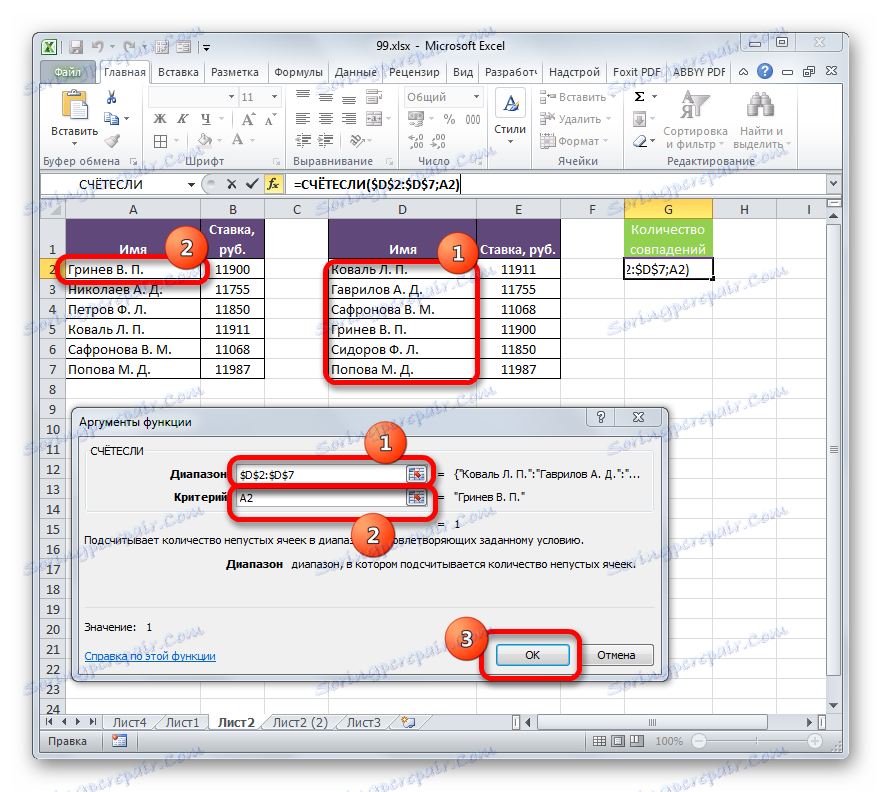
- Vyberte první prvek dalšího sloupce, ve kterém bude počítán počet shody. Potom klikněte na ikonu "Vložit funkci" .
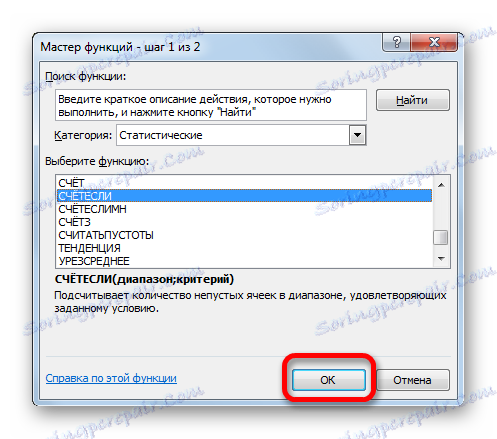
- Spustí se Průvodce funkcí . Pojďme do kategorie "Statistické" . V seznamu se nachází název "RADA" . Po jeho výběru klikněte na tlačítko "OK" .
- Zobrazí se okno argumentů operátora Rady. Jak vidíte, názvy polí v tomto okně odpovídají názvům argumentů.
Nastavte kurzor do pole "Rozsah" . Poté přidržením levého tlačítka myši vyberte všechny hodnoty sloupce s názvy druhé tabulky. Jak vidíte, souřadnice se okamžitě dostanou do zadaného pole. Pro naše účely je však tato adresa absolutní. Chcete-li to provést, vyberte souřadnice v poli a stiskněte klávesu F4 .
Jak vidíte, spojka měla absolutní podobu, která je charakterizována přítomností znaků dolaru.
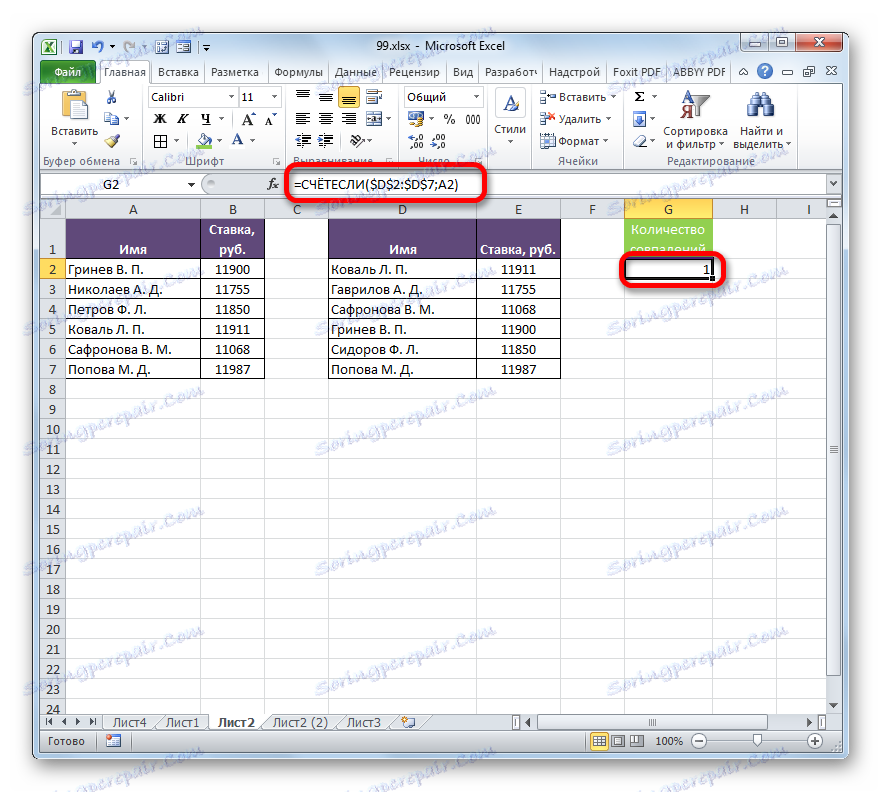
Poté přejděte na pole "Kritérium" a nastavte kurzor tam. Klepněte na první prvek s názvy v prvním rozsahu tabulky. V tomto případě ponecháme referenční relativní. Po zobrazení v poli můžete kliknout na tlačítko "OK" .
- Výsledek se zobrazí v elementu listu. To se rovná číslu "1" . To znamená, že v seznamu názvů druhé tabulky se vyskytuje příjmení "Grinev VP" , které je první v seznamu prvního tabulkového pole.
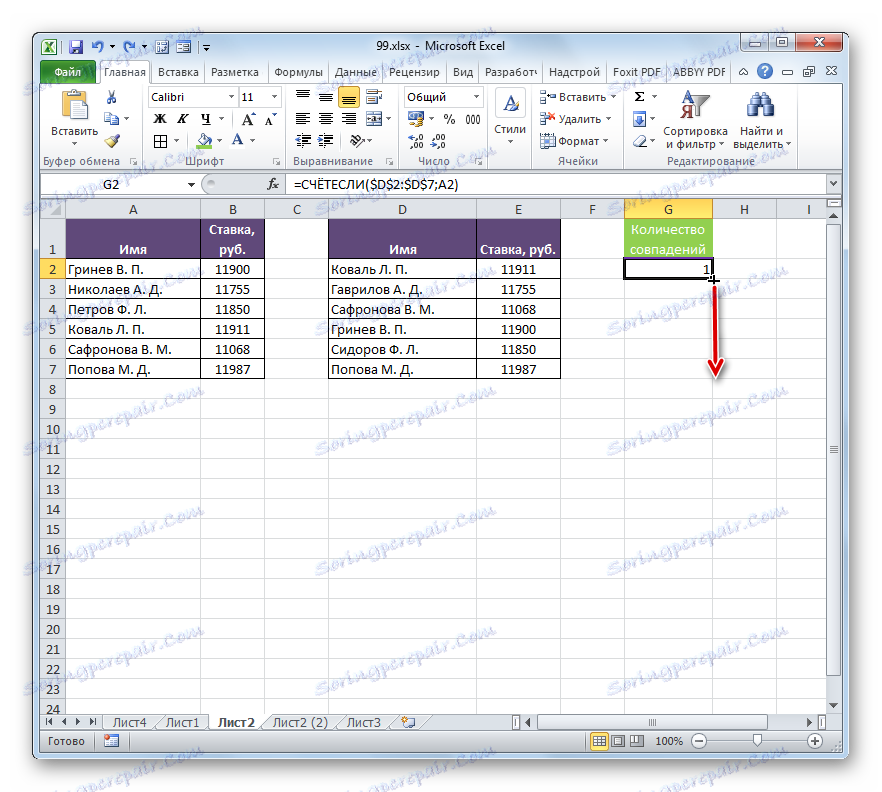
- Nyní musíme vytvořit podobný výraz pro všechny ostatní prvky první tabulky. Chcete-li to provést, proveďte kopírování pomocí značky pro vyplnění, jak jsme učinili dříve. Umístěte kurzor do pravé dolní části listového prvku, který obsahuje funkci COUNTIF a po jeho převedení na značku naplnění zatlačíme levým tlačítkem myši a přetáhněte kurzor dolů.
- Jak je vidět, program provedl výpočet koincidencí porovnáním každé buňky první tabulky s daty, která jsou umístěna v druhém rozsahu tabulky. Ve čtyřech případech byl výsledek "1" a ve dvou případech "0" . To znamená, že program nemohl najít ve druhé tabulce dvě hodnoty, které jsou k dispozici v prvním tabulkovém poli.
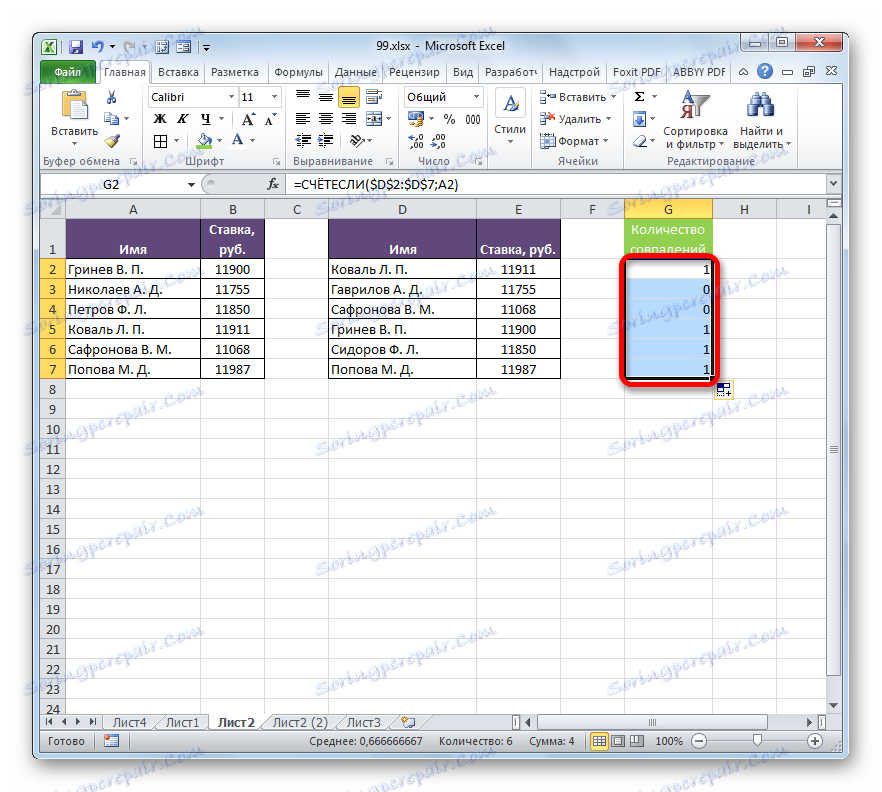
Samozřejmě, že tento výraz pro porovnání tabulkových ukazatelů, můžete použít ve stávající podobě, ale existuje možnost jej zlepšit.
Hodnoty, které jsou k dispozici v druhé tabulce, ale nikoliv v první tabulce, se zobrazí v samostatném seznamu.
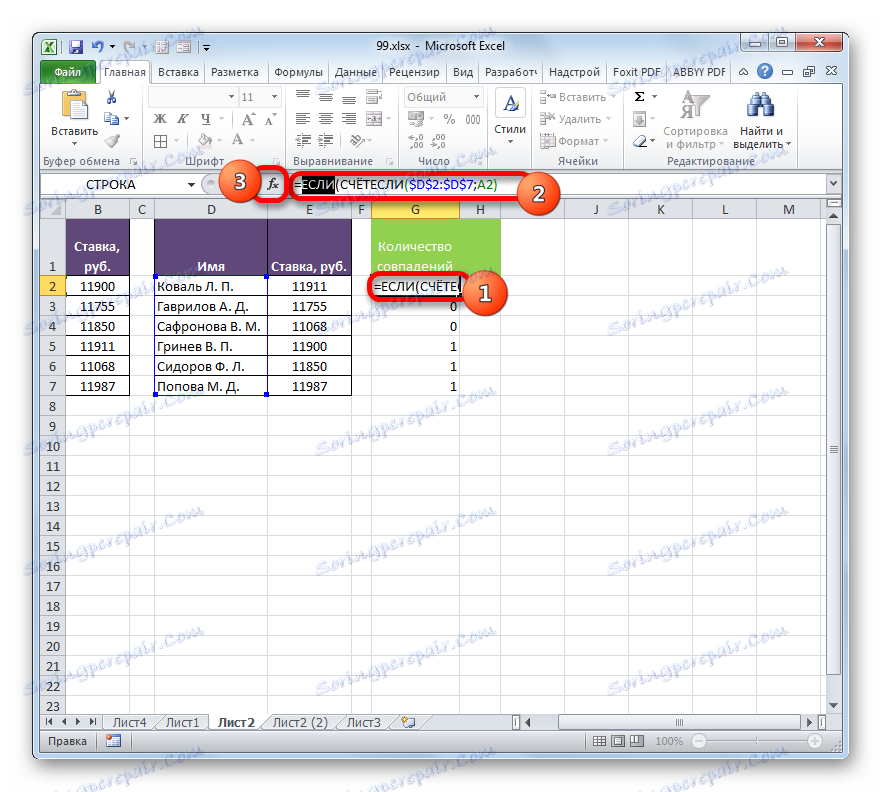
- Především budeme přepracovat náš vzorec pro COUNTRY , trochu to učiníme jedním z argumentů operátora IF . Chcete-li to provést, vyberte první buňku, ve které je umístěn operátor ZEMĚ . V řádku vzorců před tím přidáme výraz "IF" bez uvozovek a otevřete konzolu. Dále, abychom usnadnili práci, zvolíme v řádku vzorce hodnotu "IF" a klikneme na ikonu "Vložit funkci" .
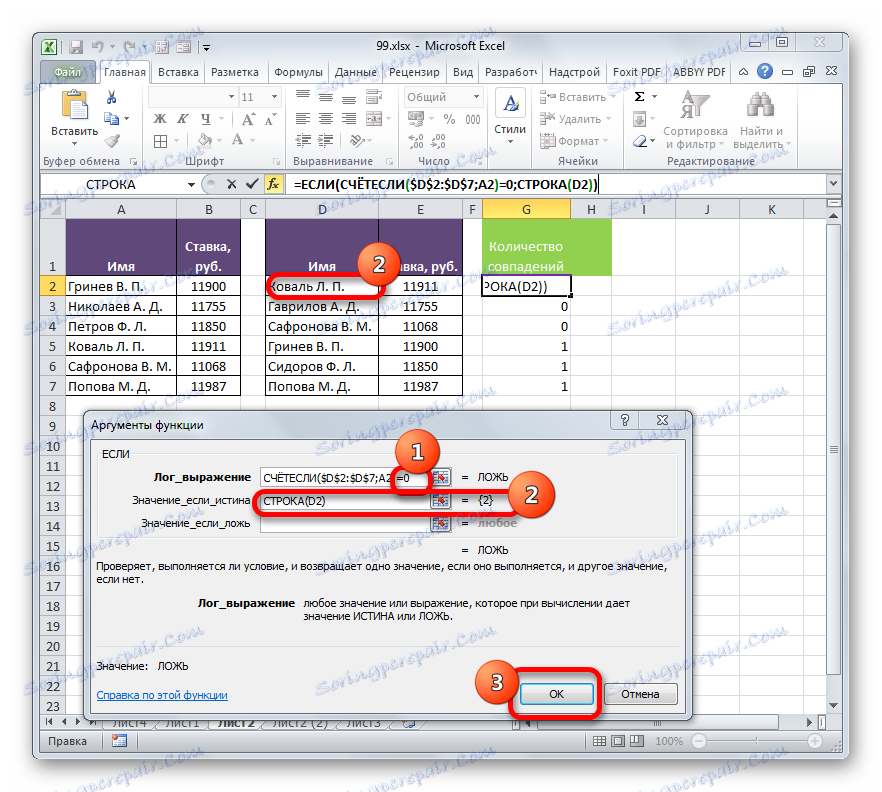
- Otevře se okno argumentu funkce IF . Jak vidíte, první pole okna je již obsazeno hodnotou operátora Rady. Ale musíme dokončit něco jiného v této oblasti. Kurzor tam nastavíme a do již existujícího výrazu přidáme "= 0" bez uvozovek.
Poté přejděte na pole Hodnota, pokud je pravda . Zde budeme používat jednu další vnořenou funkci - STRING . Zadáváme slovo "LINE" bez uvozovek, pak otevřete závorky a ve druhé tabulce určíte souřadnice první buňky s posledním jménem a pak zavřete závorky. Konkrétně v našem případě v poli "Hodnota, pokud je pravda" byl získán následující výraz:
СТРОКА(D2)Nyní příkaz LINE nahlásí funkci, pokud je číslo řádku, ve kterém je konkrétní příjmení umístěno, a pokud je splněna podmínka uvedená v prvním poli, funkce IF vytiskne toto číslo do buňky. Klikněte na tlačítko "OK" .
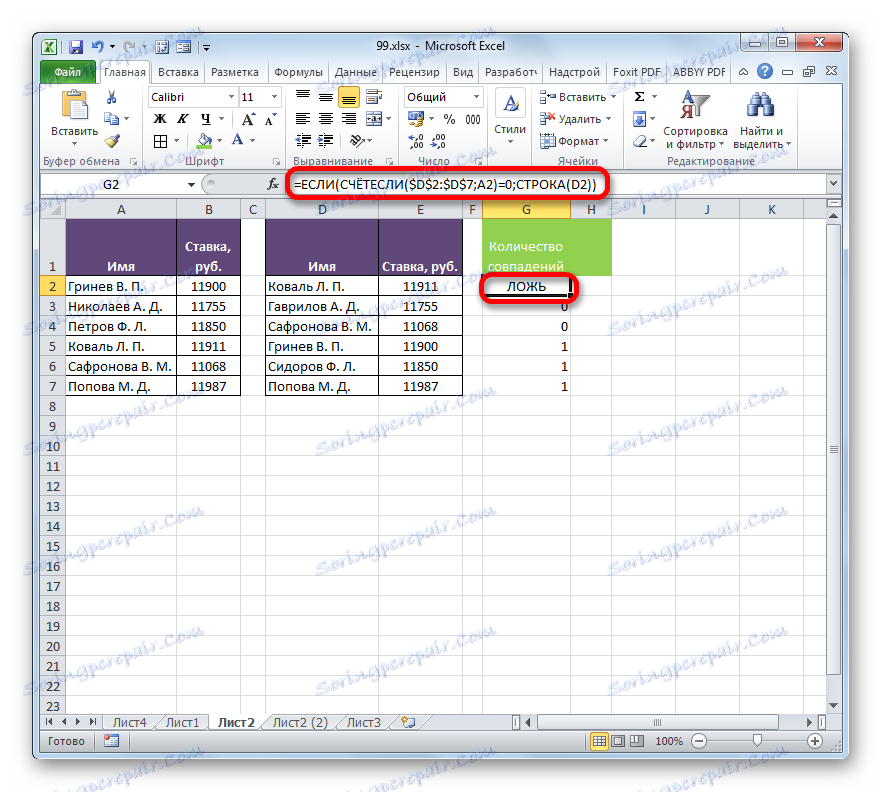
- Jak vidíte, první výsledek se zobrazí jako "FALSE" . To znamená, že hodnota nesplňuje podmínky provozovatele IF . To znamená, že první příjmení je v obou seznamech.
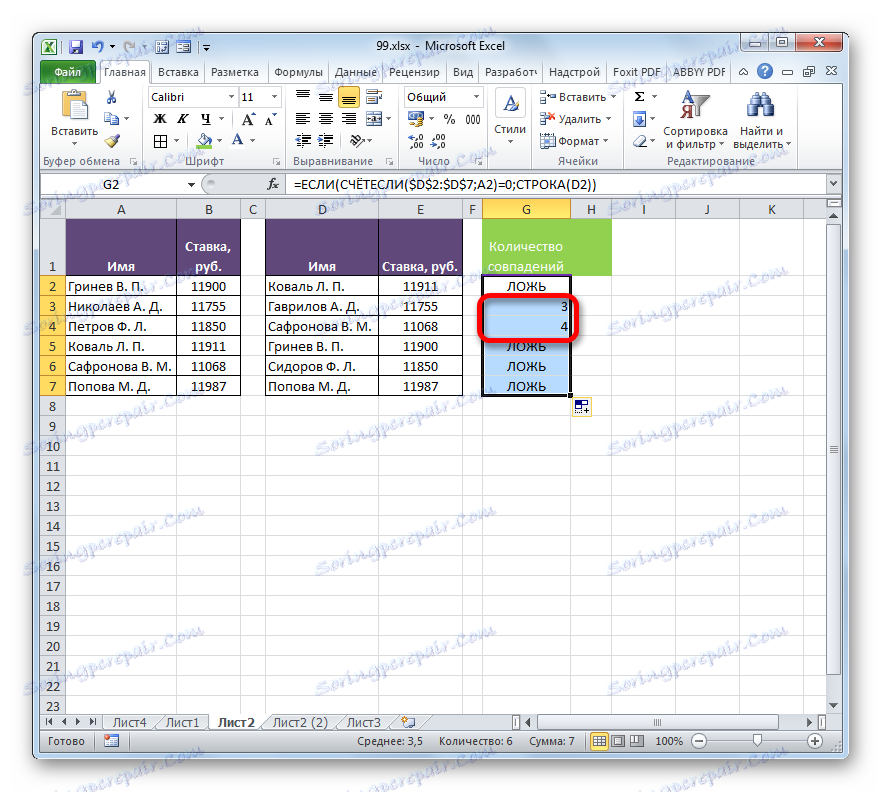
- Pomocí značky naplnění zkopírujeme výraz operátora IF na celý sloupec obvyklým způsobem. Jak vidíte, u dvou položek, které se nacházejí ve druhé tabulce, ale nikoli v první tabulce, vzorec udává čísla řádků.
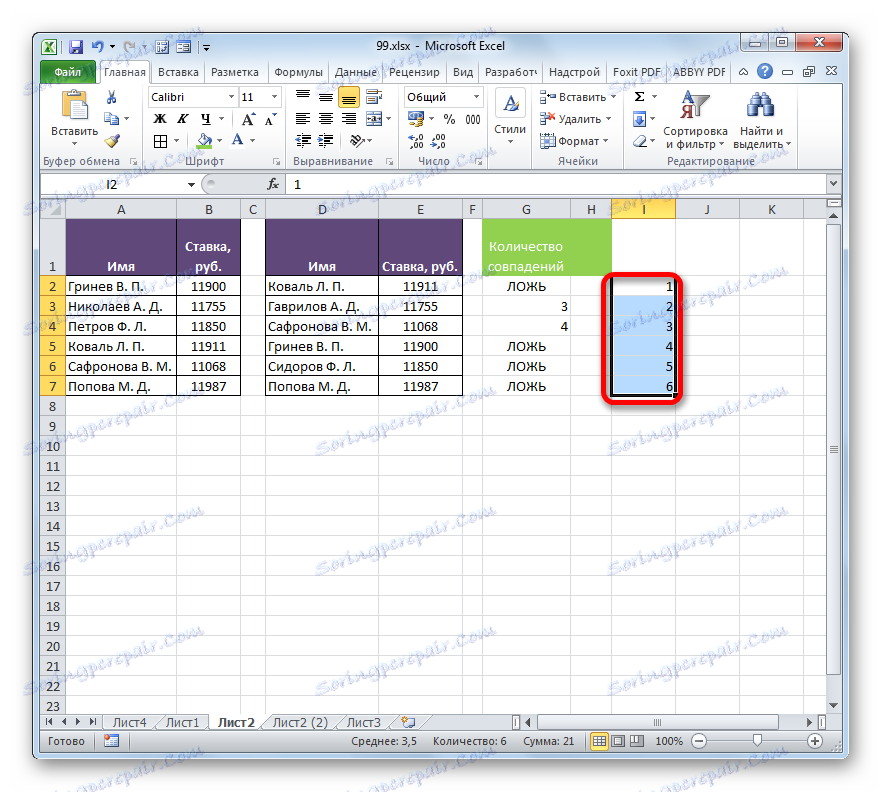
- Odstoupíme z tabulky směrem doprava a vyplníme sloupec čísly v pořadí od 1 . Количество номеров должно совпадать с количеством строк во второй сравниваемой таблице. Чтобы ускорить процедуру нумерации, можно также воспользоваться маркером заполнения.
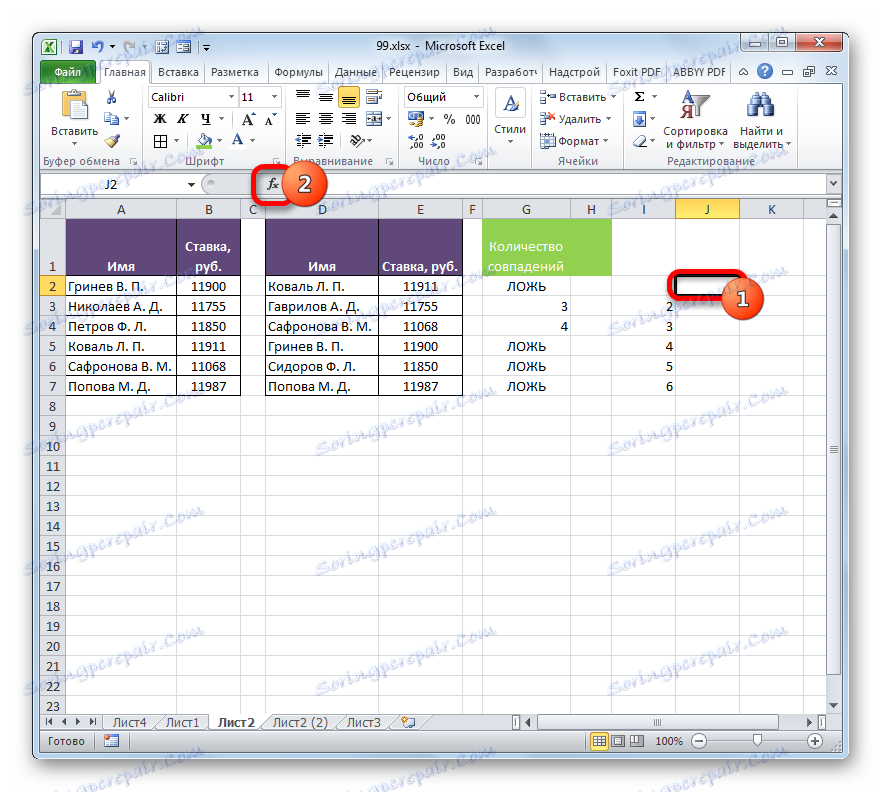
- После этого выделяем первую ячейку справа от колонки с номерами и щелкаем по значку «Вставить функцию» .
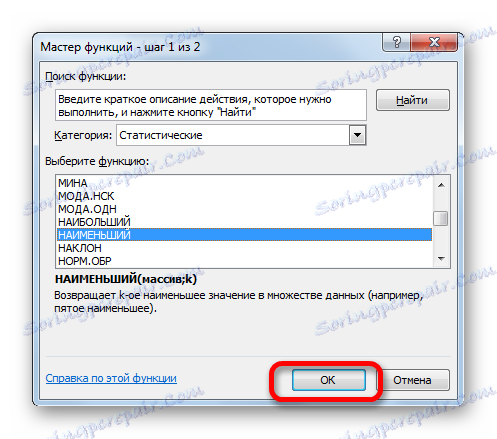
- Otevře se Průvodce funkcí . Переходим в категорию «Статистические» и производим выбор наименования «НАИМЕНЬШИЙ» . Klepněte na tlačítko "OK" .
- Функция НАИМЕНЬШИЙ , окно аргументов которой было раскрыто, предназначена для вывода указанного по счету наименьшего значения.
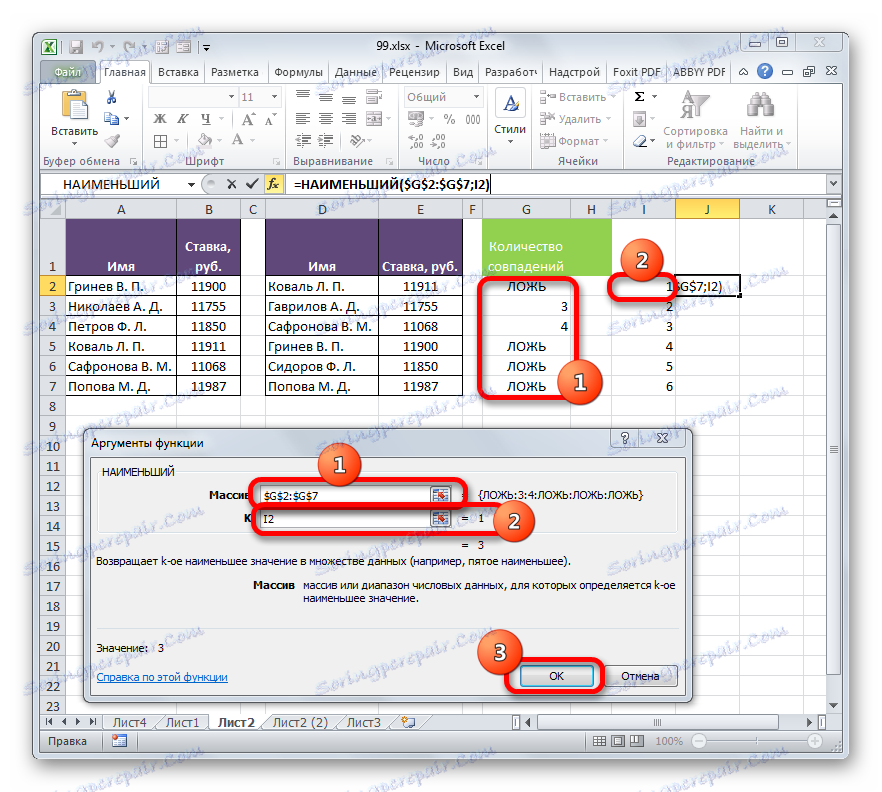
В поле «Массив» следует указать координаты диапазона дополнительного столбца «Количество совпадений» , который мы ранее преобразовали с помощью функции ЕСЛИ . Делаем все ссылки абсолютными.
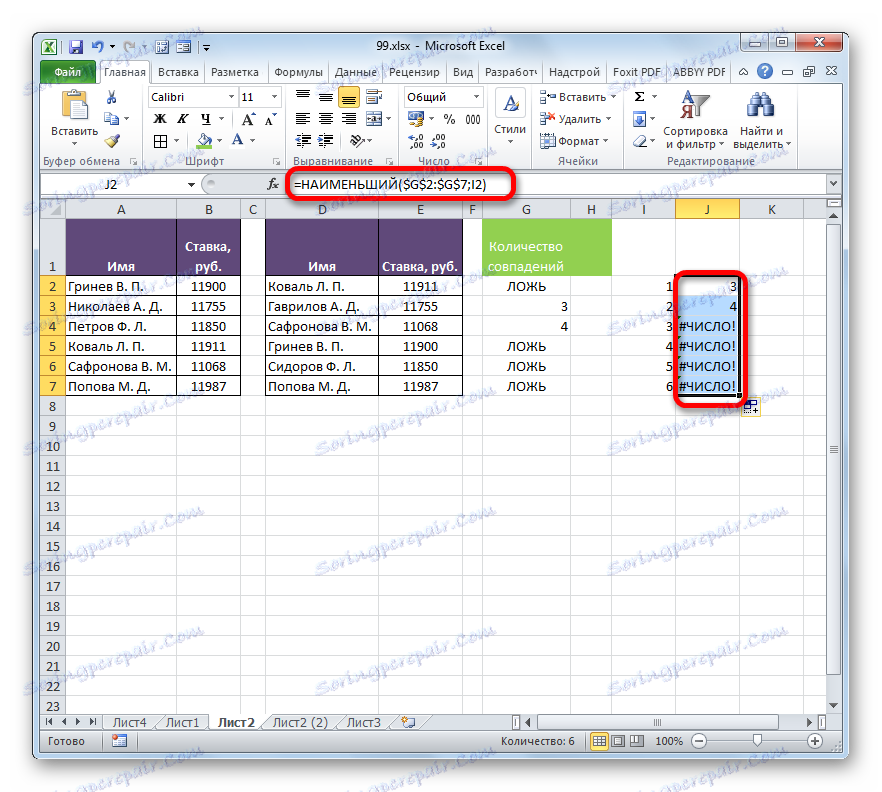
В поле «K» указывается, какое по счету наименьшее значение нужно вывести. Тут указываем координаты первой ячейки столбца с нумерацией, который мы недавно добавили. Адрес оставляем относительным. Klepněte na tlačítko "OK" .
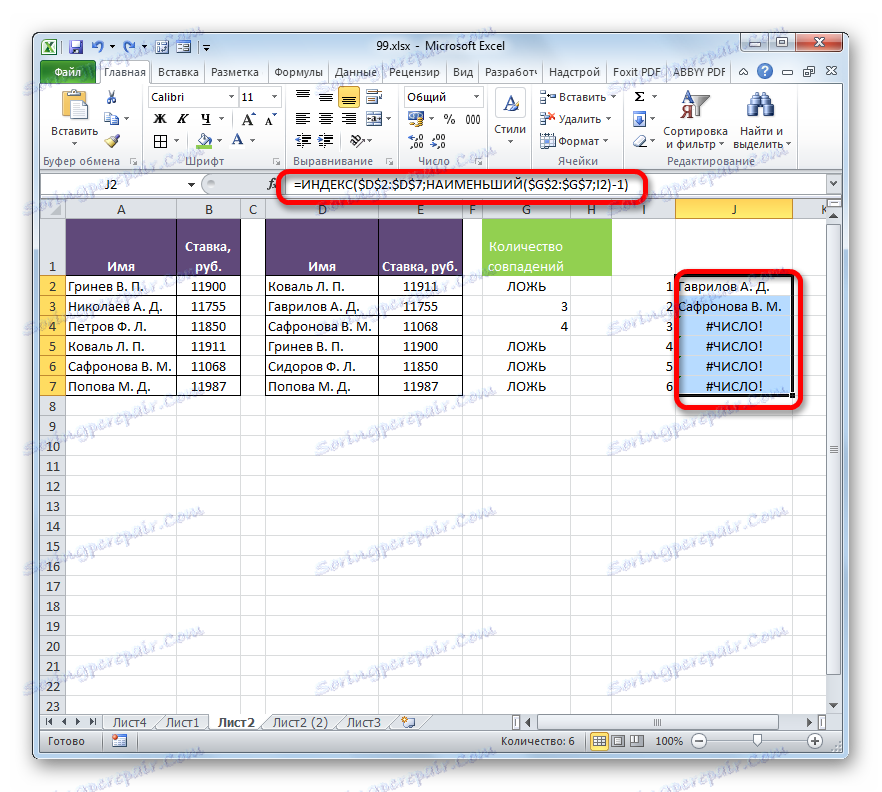
- Оператор выводит результат – число 3 . Именно оно наименьшее из нумерации несовпадающих строк табличных массивов. С помощью маркера заполнения копируем формулу до самого низа.
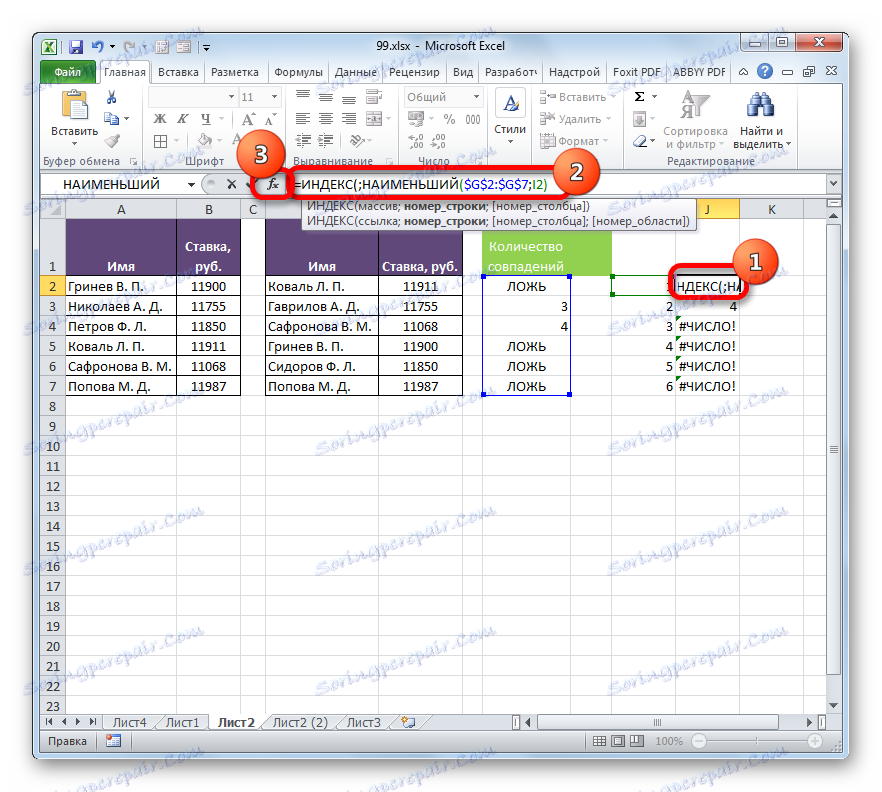
- Теперь, зная номера строк несовпадающих элементов, мы можем вставить в ячейку и их значения с помощью функции ИНДЕКС . Выделяем первый элемент листа, содержащий формулу НАИМЕНЬШИЙ . После этого переходим в строку формул и перед наименованием «НАИМЕНЬШИЙ» дописываем название «ИНДЕКС» без кавычек, тут же открываем скобку и ставим точку с запятой ( ; ). Затем выделяем в строке формул наименование «ИНДЕКС» и кликаем по пиктограмме «Вставить функцию» .
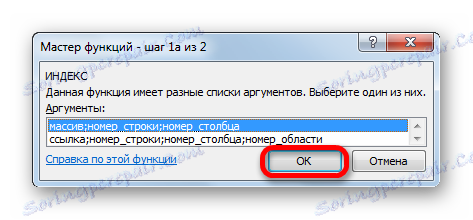
- После этого открывается небольшое окошко, в котором нужно определить, ссылочный вид должна иметь функция ИНДЕКС или предназначенный для работы с массивами. Нам нужен второй вариант. Он установлен по умолчанию, так что в данном окошке просто щелкаем по кнопке «OK» .
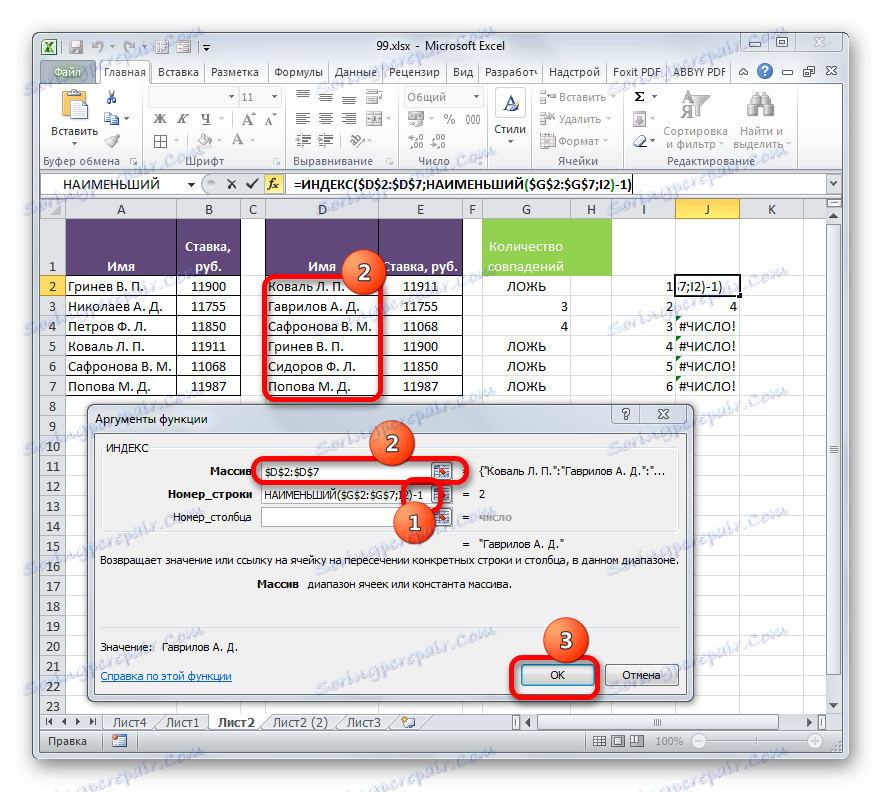
- Запускается окно аргументов функции ИНДЕКС . Данный оператор предназначен для вывода значения, которое расположено в определенном массиве в указанной строке.
Как видим, поле «Номер строки» уже заполнено значениями функции НАИМЕНЬШИЙ . От уже существующего там значения следует отнять разность между нумерацией листа Excel и внутренней нумерацией табличной области. Как видим, над табличными значениями у нас только шапка. Это значит, что разница составляет одну строку. Поэтому дописываем в поле «Номер строки» значение «-1» без кавычек.
В поле «Массив» указываем адрес диапазона значений второй таблицы. При этом все координаты делаем абсолютными, то есть, ставим перед ними знак доллара уже ранее описанным нами способом.
Klikněte na tlačítko "OK" .
- После вывода результат на экран протягиваем функцию с помощью маркера заполнения до конца столбца вниз. Как видим, обе фамилии, которые присутствуют во второй таблице, но отсутствуют в первой, выведены в отдельный диапазон.
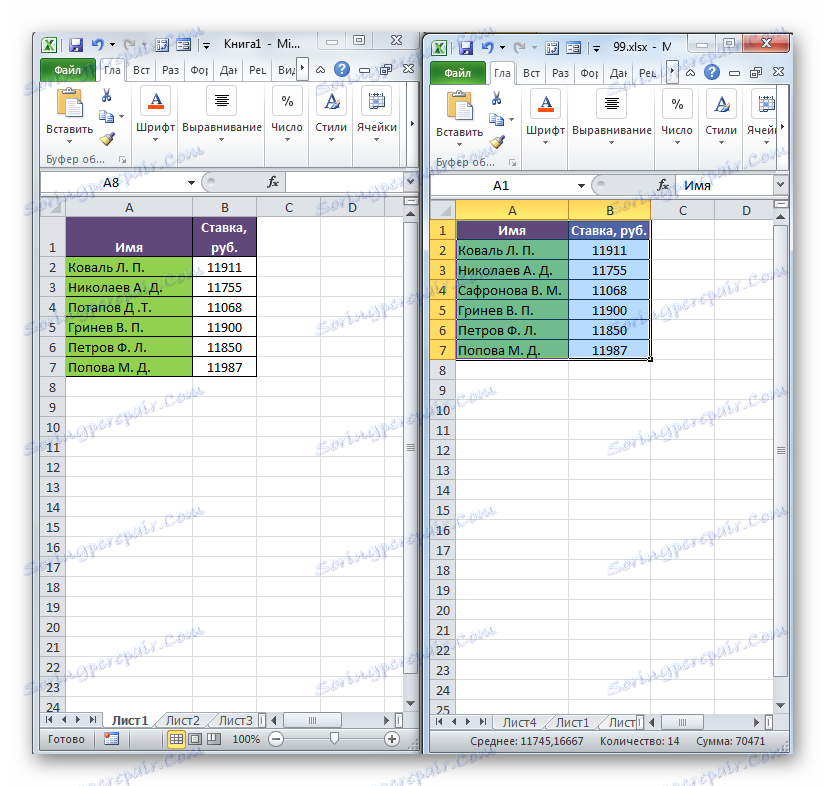
Способ 5: сравнение массивов в разных книгах
При сравнении диапазонов в разных книгах можно использовать перечисленные выше способы, исключая те варианты, где требуется размещение обоих табличных областей на одном листе. Главное условие для проведения процедуры сравнения в этом случае – это открытие окон обоих файлов одновременно. Для версий Excel 2013 и позже, а также для версий до Excel 2007 с выполнением этого условия нет никаких проблем. Но в Excel 2007 и Excel 2010 для того, чтобы открыть оба окна одновременно, требуется провести дополнительные манипуляции. Как это сделать рассказывается в отдельном уроке.
Lekce: Как открыть Эксель в разных окнах
Как видим, существует целый ряд возможностей сравнить таблицы между собой. Какой именно вариант использовать зависит от того, где именно расположены табличные данные относительно друг друга (на одном листе, в разных книгах, на разных листах), а также от того, как именно пользователь желает, чтобы это сравнение выводилось на экран.