Rozpoznat text v souboru PDF online.
Není vždy možné extrahovat text ze souboru PDF pomocí běžného kopírování. Často jsou stránky takových dokumentů naskenované obsahy jejich papírových verzí. Pro převedení takových souborů na plně upravitelné textové údaje se používají speciální programy s funkcí optického rozpoznávání znaků (OCR).
Taková řešení jsou velmi obtížně realizovatelná a proto stojí spoustu peněz. Pokud potřebujete pravidelně rozpoznávat text s PDF, je vhodné zakoupit příslušný program. Ve vzácných případech by bylo logičtější používat jednu z dostupných služeb online s podobnými funkcemi.
Obsah
Jak rozpoznat text z PDF online
Samozřejmě, soubor funkcí OCR online služeb je mnohem omezenější v porovnání s plnými desktopovými řešeními. Ale s těmito prostředky můžete pracovat buď zdarma, nebo za poplatek. Hlavní věc spočívá v tom, že odpovídající webové aplikace zvládnou svůj hlavní úkol, a to rozpoznávání textu.
Metoda 1: ABBYY FineReader Online
Společnost pro vývoj služeb je jedním z vůdců v oblasti rozpoznávání optických dokumentů. ABBYY FineReader pro Windows a Mac je výkonné řešení pro konverzi PDF do textu a další práci s ním.
Webový protějšek programu, samozřejmě, je v jeho funkčnosti horší. Nicméně služba dokáže rozpoznat text ze skenů a fotografií ve více než 190 jazycích. Podporuje konverzi souborů PDF do dokumentů Slovo , Excel atd.
Online služba ABBYY FineReader Online
- Než začnete pracovat s nástrojem, vytvořte účet na webu nebo se přihlaste pomocí účtu Facebook, Google nebo Microsoft.
![Zaregistrujte se v programu ABBYY FineReader Online]()
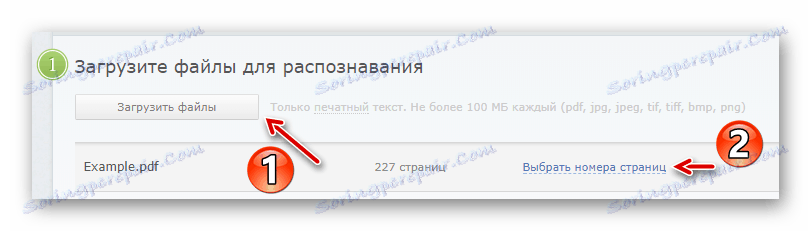
Chcete-li přejít do přihlašovacího okna, klikněte na tlačítko "Přihlásit" v horní liště nabídek. - Po přihlášení importujte požadovaný dokument PDF do programu FineReader pomocí tlačítka Nahrát soubory .
![Rozpoznávání textu z dokumentu PDF v online službě ABBYY FineReader Online]()
Poté klikněte na "Vybrat čísla stránek" a zadejte požadovaný interval pro rozpoznávání textu. - Dále vyberte jazyky v dokumentu, formát výsledného souboru a klikněte na tlačítko "Rozpoznat" .
![Spusťte rozpoznávání textu z dokumentu PDF v aplikaci ABBYY FineReader Online]()
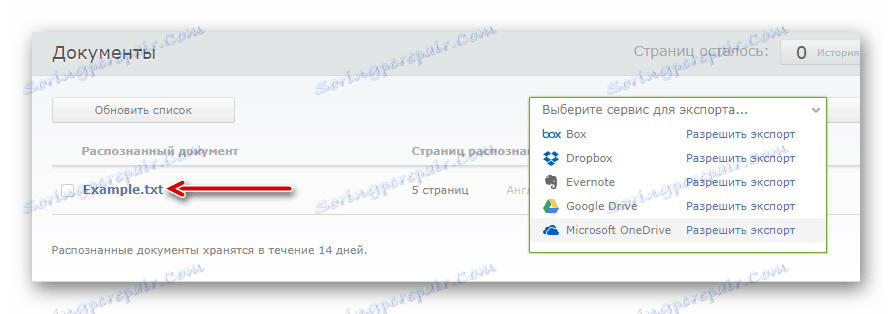
- Po zpracování, jehož délka závisí zcela na velikosti dokumentu, můžete stáhnout hotový soubor s textovými údaji jednoduše kliknutím na jeho název.
![Stažení dokončeného dokumentu ze služby online ABBYY FineReader Online]()
Nebo je exportujte do některé z dostupných cloudových služeb.

Tato služba se pravděpodobně vyznačuje nejpřesnějšími algoritmy rozpoznávání textu na obrázcích a souborech PDF. Bohužel, jeho volné využití je omezeno na pět stránek zpracovaných za měsíc. Chcete-li pracovat s rozsáhlejšími dokumenty, musíte si zakoupit roční předplatné.
Pokud je však funkce OCR velmi zřídka potřebná, ABBYY FineReader Online je skvělá volba pro extrakci textu z malých souborů PDF.
Metoda 2: OCR zdarma
Jednoduchá a pohodlná služba pro digitalizaci textu. Bez nutnosti registrace, zdroj vám umožní rozpoznat 15 úplných PDF stránek za hodinu. Free OCR plně spolupracuje s dokumenty ve 46 jazycích a bez oprávnění podporuje tři formáty exportu textu - DOCX, XLSX a TXT.
Při registraci je uživatel schopen zpracovat vícestranové dokumenty, ale volný počet těchto stránek je omezen na 50 jednotek.
- Chcete-li rozpoznat text z PDF jako "hosta" bez povolení na prostředku, použijte příslušný formulář na hlavní stránce webu.
![Rozpoznávání PDF v online OCR službě Free Online]()
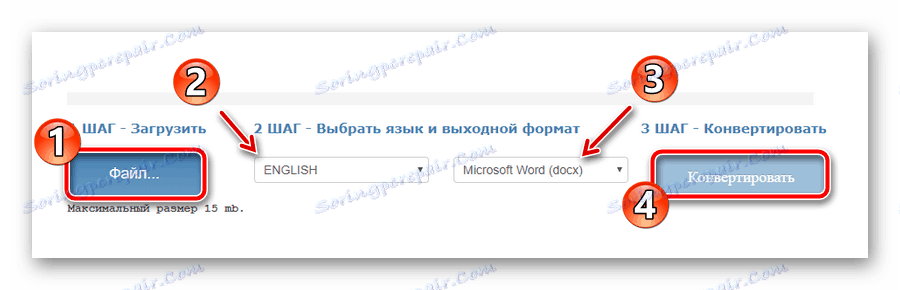
Vyberte požadovaný dokument pomocí tlačítka "Soubor" , vyberte hlavní textový jazyk, výstupní formát, počkejte na stažení souboru a klikněte na tlačítko "Převést" . - Na konci procesu digitalizace klikněte na "Stažení výstupního souboru" pro uložení hotového dokumentu s textem na vašem počítači.
![Stažení výsledku rozpoznávání textu z PDF z online služby OCR zdarma]()
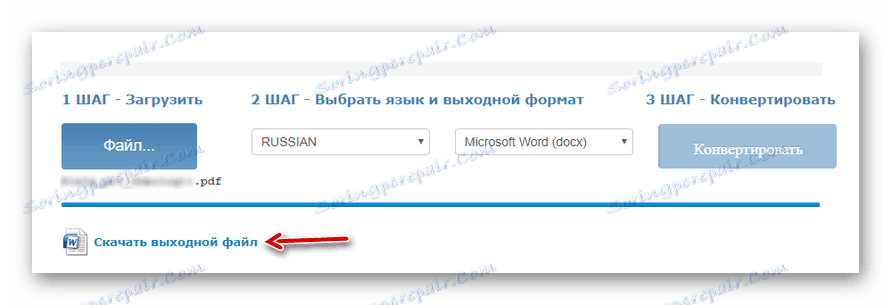
Pro oprávněné uživatele je posloupnost akcí poněkud odlišná.
- Použijte tlačítko "Registrace" nebo "Přihlášení" v horní liště nabídek pro vytvoření nebo přístup ke svému bezplatnému účtu OCR.
![Vytvoření účtu v on-line službě Online OCR zdarma]()
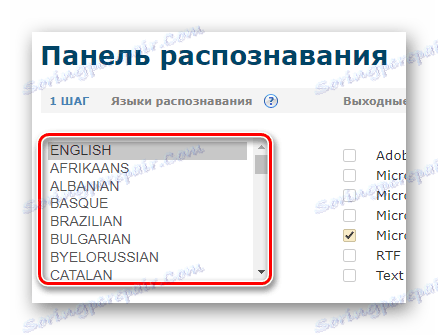
- Po autorizaci v panelu pro rozpoznávání podržte stisknutou klávesu CTRL a z příslušného seznamu vyberte dva jazyky zdrojového dokumentu.
![Určení jazyků zdrojového dokumentu pro rozpoznávání textu v aplikaci Free Online OCR]()
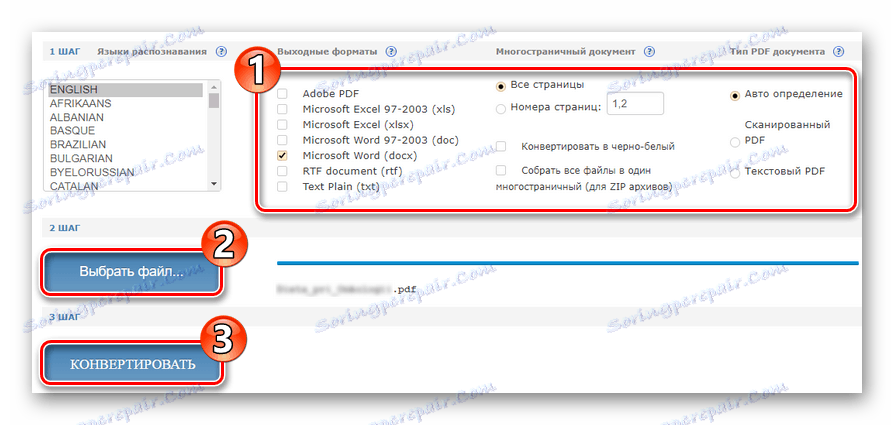
- Určete další parametry pro extrakci textu z PDF a klepnutím na tlačítko "Vybrat soubor" přeneste dokument do služby.
![Začněte uznání dokumentu PDF v on-line službě OCR zdarma]()
Poté spusťte rozpoznávání kliknutím na tlačítko "Převést" . - Po zpracování dokumentu klepněte na odkaz s názvem výstupního souboru v příslušném sloupci.
![Stažení hotového souboru DOCX z online služby OCR zdarma]()
Výsledek rozpoznávání bude okamžitě uložen do paměti vašeho počítače.
Pokud potřebujete extrahovat text z malého dokumentu PDF, můžete bezpečně použít nástroj popsaný výše. Chcete-li pracovat s velkými soubory, budete muset ve Free Online OCR kupovat další symboly nebo se uchýlit k jinému řešení.
Metoda 3: NewOCR
Úplně bezplatná služba OCR, která umožňuje extrahovat text z prakticky všech grafických a elektronických dokumentů, jako je DjVu a PDF. Prostředek neomezuje velikost a počet rozpoznatelných souborů, nevyžaduje registraci a nabízí širokou škálu souvisejících funkcí.
NewOCR podporuje 106 jazyků a dokáže správně zpracovat i nekvalitní skenování dokumentů. Ruční výběr oblasti pro rozpoznávání textu je možné na stránce souboru.
- Takže můžete okamžitě začít pracovat s prostředkem, aniž byste museli provádět zbytečné akce.
![Stažení PDF souboru uznání online služby NewOCR]()
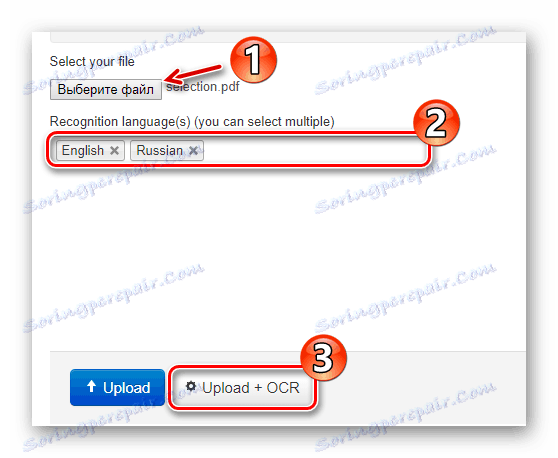
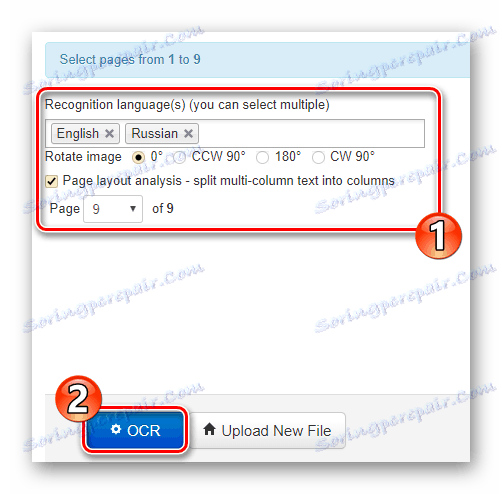
Přímo na hlavní stránce je formulář pro import dokumentu na web. Chcete-li soubor načíst do složky NewOCR, použijte v části "Vyberte soubor" tlačítko "Vybrat soubor" . Poté v poli "Jazyky rozpoznávání" vyberte jeden nebo více jazyků původního dokumentu a poté klikněte na tlačítko "Nahrát + OCR" . - Nastavte preferované nastavení rozpoznávání, vyberte požadovanou stránku a stáhněte text a klikněte na tlačítko "OCR" .
![Nastavení a spuštění rozpoznávání textu z PDF v online službě NewOCR]()
- Přejděte níže a najděte tlačítko "Stáhnout" .
![Stáhnout text extrahovaný do NewOCR do počítače]()
Klikněte na něj a v rozevíracím seznamu vyberte požadovaný formát dokumentu pro stahování. Poté bude hotový soubor s extrahovaným textem stažen do vašeho počítače.
Nástroj je vhodný a rozpozná všechny znaky v dostatečně vysoké kvalitě. Zpracování každé stránky importovaného dokumentu PDF však musí být spuštěno nezávisle a zobrazeno v samostatném souboru. Můžete samozřejmě okamžitě zkopírovat výsledky rozpoznávání do schránky a sloučit je s ostatními.
Vzhledem k výše uvedenému nuanci je však obtížné získat značné množství textu pomocí nástroje NewOCR. Služba se vyrovnává s malými soubory "s třeskem."
Metoda 4: OCR.Space
Jednoduchý a srozumitelný prostředek pro digitalizaci textu umožňuje rozpoznávat dokumenty ve formátu PDF a vytisknout výsledek do souboru TXT. Počet stránek není omezen. Jediným omezením je, že velikost vstupního dokumentu by neměla překročit 5 megabajtů.
- Přihlášení k práci s nástrojem není nutné.
![Importujte soubor PDF do služby OCR.Space online]()
Jednoduše klikněte na výše uvedený odkaz a nahrajte dokument PDF na webové stránky z počítače pomocí tlačítka "Vybrat soubor" nebo ze sítě kliknutím na odkaz. - V rozevíracím seznamu Vybrat jazyk OCR vyberte jazyk importovaného dokumentu.
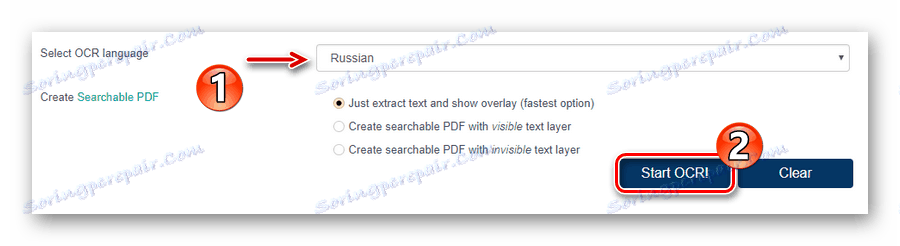
![Spuštění procesu rozpoznávání dokumentu PDF v online službě OCR.Space]()
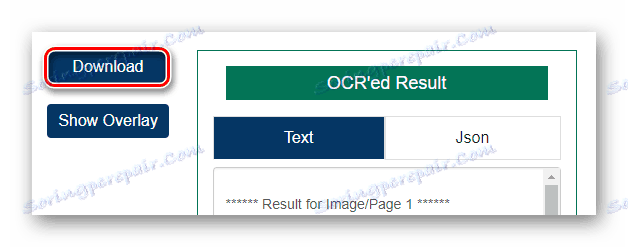
Potom spusťte proces rozpoznávání textu kliknutím na tlačítko "Spustit OCR!" . - Na konci zpracování souboru zkontrolujte výsledek v poli "OCR'ed Result" a klikněte na "Stáhnout" a stáhněte si hotový dokument TXT.
![Stažení výsledku rozpoznávání souboru PDF z online služby OCR.Space]()

Pokud stačí vybírat text z PDF a konečné formátování není vůbec důležité, OCR.Space je dobrá volba. Jediný dokument musí být "jednojazyčný", jelikož není ve službě uznáno dva nebo více jazyků současně.
Viz též: Bezplatné analogy programu FineReader
Při vyhodnocování online nástrojů uvedených v článku je třeba poznamenat, že ABBYY FineReader Online zpracovává funkci OCR nejpřesněji a nejpřesněji. Pokud je pro vás důležitá maximální přesnost rozpoznávání textu, je vhodné tuto konkrétní možnost zvážit. Ale platit za to, s největší pravděpodobností, musí také.
Pokud potřebujete digitalizovat drobné dokumenty a jste připraveni opravit chyby ve službě sami, doporučujeme použít NewOCR, OCR.Space nebo Free OCR.