Aplikace funkce BPR v aplikaci Microsoft Excel
V některých případech je uživatel konfrontován s úkolem vrátit určitý počet znaků do cílové buňky z jiné buňky, počínaje znaménkem uvedeným na účtu vlevo. Tato funkce je dokonale ovládána funkcí PCR . Ještě více zvyšuje jeho funkčnost, pokud v kombinaci s ní používá jiné operátory, například SEARCH nebo FIND . Podívejme se blíže na to, jaké jsou funkce CCT a uvidíme, jak funguje na konkrétních příkladech.
Obsah
Použití CCRT
Hlavním úkolem operátora je vybírat z určeného prvku listu určitý počet tištěných znaků, včetně mezer, počínaje znakem uvedeným na levém účtu. Tato funkce patří do kategorie textových operátorů. Jeho syntaxe je následující:
=ПСТР(текст;начальная_позиция;количество_знаков)
Jak můžete vidět, tento vzorec se skládá ze tří argumentů. Všechny jsou povinné.
Argument "Text" obsahuje adresu prvku listu, který obsahuje textový výraz s extrahovanými znaky.
Argument "Počáteční pozice" je reprezentován číslem, které označuje, které znamení z účtu, počínaje zleva, je třeba extrahovat. První znak je považován za "1" , druhý za "2" atd. Při výpočtu se berou v úvahu i mezery.
Argument "Počet znaků" obsahuje číselný index počtu znaků, počínaje počáteční pozicí, kterou je třeba extrahovat do cílové buňky. Při počítání, stejně jako v předchozím argumentu, se berou v úvahu prostory.
Příklad 1: Jediná extrakce
Pro popis příkladů aplikace funkce DCS začínáme nejjednodušším případem, kdy potřebujeme extrahovat jeden výraz. Samozřejmě, že takové možnosti jsou zřídka využívány v praxi, takže tento příklad uvádíme pouze jako úvod k principům práce operátora.
Takže máme tabulku zaměstnanců společnosti. První sloupec obsahuje jména, příjmení a patronymiku zaměstnanců. Musíme použít operátora CCTS, abychom vyňali v uvedené buňce pouze jméno první osoby ze seznamu Petra Ivanoviča Nikolajeva.
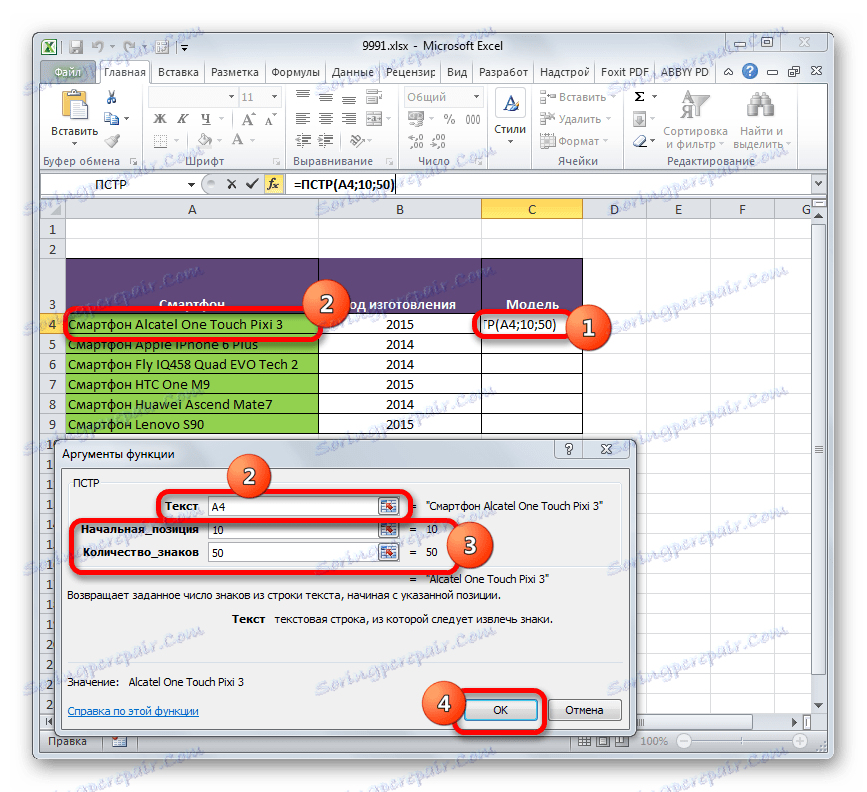
- Vyberte prvek listu, ze kterého chcete vybírat. Klepneme na tlačítko "Vložit funkci" , která se nachází poblíž řádku vzorce.
- Zobrazí se okno Průvodce volbami . Přejděte do kategorie "Text" . Vybíráme tam název "POS" a klikneme na tlačítko "OK" .
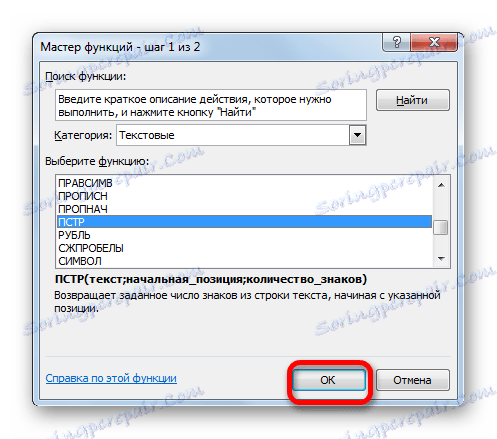
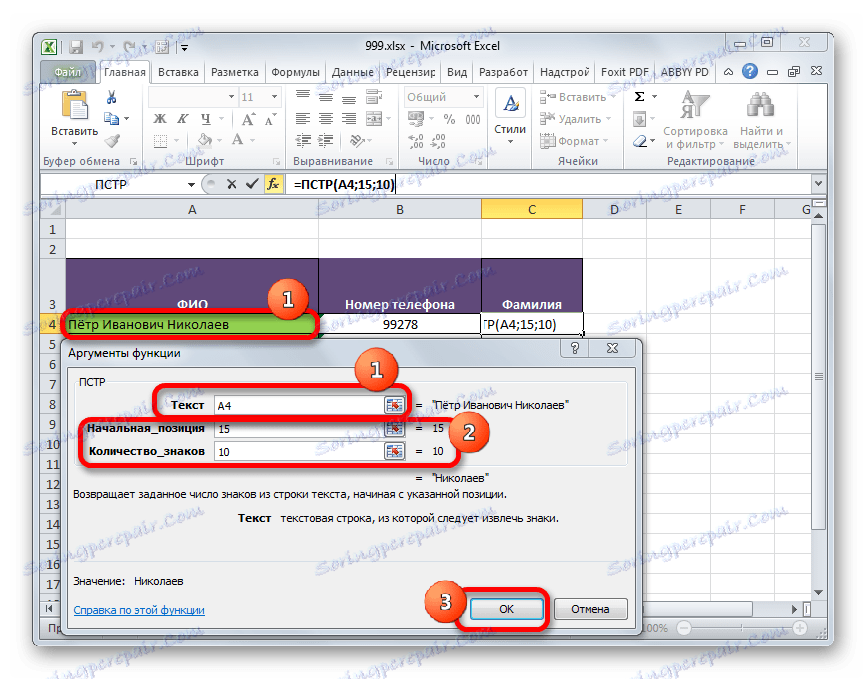
- Zobrazí se okno argumentů operátora "PTPR" . Jak vidíte, v tomto okně odpovídá počet polí počtu argumentů této funkce.
Do pole "Text" zadáme souřadnice buňky, která obsahuje jména zaměstnanců. Aby nedošlo k ručnímu zadání adresy, jednoduše vložte kurzor do pole a klikněte levým tlačítkem myši na prvek na listu, který obsahuje potřebná data.
V poli "Počáteční pozice" musíte zadat číslo symbolu, počítané vlevo, od kterého začíná příjmení zaměstnance. Při počítání zohledňujeme také mezery. Písmeno "N" , s nímž začíná jméno zaměstnance Nikolaev, je patnáctý symbol. Proto v poli uvedeme číslo "15" .
Do pole "Počet znaků" zadejte počet znaků, které tvoří příjmení. Skládá se z osmi znaků. Ale vzhledem k tomu, že po jménu v buňce nejsou další znaky, můžeme zadat další znaky. To znamená, že v našem případě můžete zadat libovolné číslo, které se rovná nebo je větší než osm. Napsali jsme například číslo "10" . Ale jestliže po příjmení v buňce byly ještě slova, čísla nebo jiné symboly, pak bychom museli stanovit pouze přesný počet znaků ( "8" ).
Po zadání všech údajů klikněte na tlačítko "OK" .
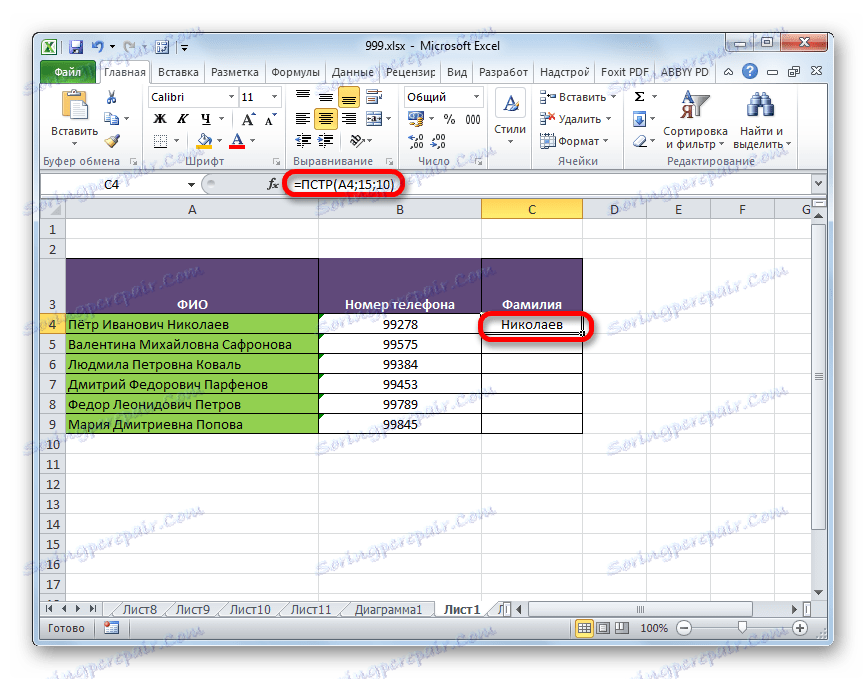
- Jak vidíte, po tomto kroku bylo příjmení zaměstnance odvozeno do buňky indikované v prvním kroku příkladu 1 .
Lekce: Průvodce funkcemi v aplikaci Excel
Příklad 2: skupinová extrakce
Ovšem samozřejmě je pro praktické účely snadnější ručně řídit jedno příjmení, než použít vzorec pro toto. Ovšem pro přenos skupiny dat bude použití funkce zcela vhodné.
Máme seznam smartphonů. Před názvem každého modelu je slovo "Smartphone" . Musíme do samostatného sloupce uvést pouze jména modelů bez tohoto slova.
- Vyberte první prázdný prvek sloupce, do kterého bude výsledek vygenerován, a zavolejte okno argumentu operátoru DTR stejným způsobem jako v předchozím příkladu.
V poli "Text" specifikujeme adresu prvního prvku sloupce s původními údaji.
V poli "Počáteční pozice" musíme zadat číslo symbolu, ze kterého budou data extrahována. V našem případě je v každé buňce před názvem modelu slovo "Smartphone" a mezera. Takže fráze, která musí být vyvedena v samostatné buňce, začíná všude od desátého symbolu. V tomto poli nastavte číslo "10" .
Do pole "Počet znaků" musíte nastavit počet znaků, které obsahují zobrazenou frázi. Jak vidíte, název každého modelu má jiný počet znaků. Ale skutečnost, že po názvu modelu, text v buňkách končí, uloží situaci. Proto můžeme v tomto poli nastavit libovolné číslo, které se rovná nebo je větší než počet znaků v nejdelším názvu tohoto seznamu. Nastavili jsme libovolný počet znaků "50" . Název kteréhokoli ze zmíněných smartphonů nepřesahuje 50 znaků, takže tato volba nám vyhovuje.
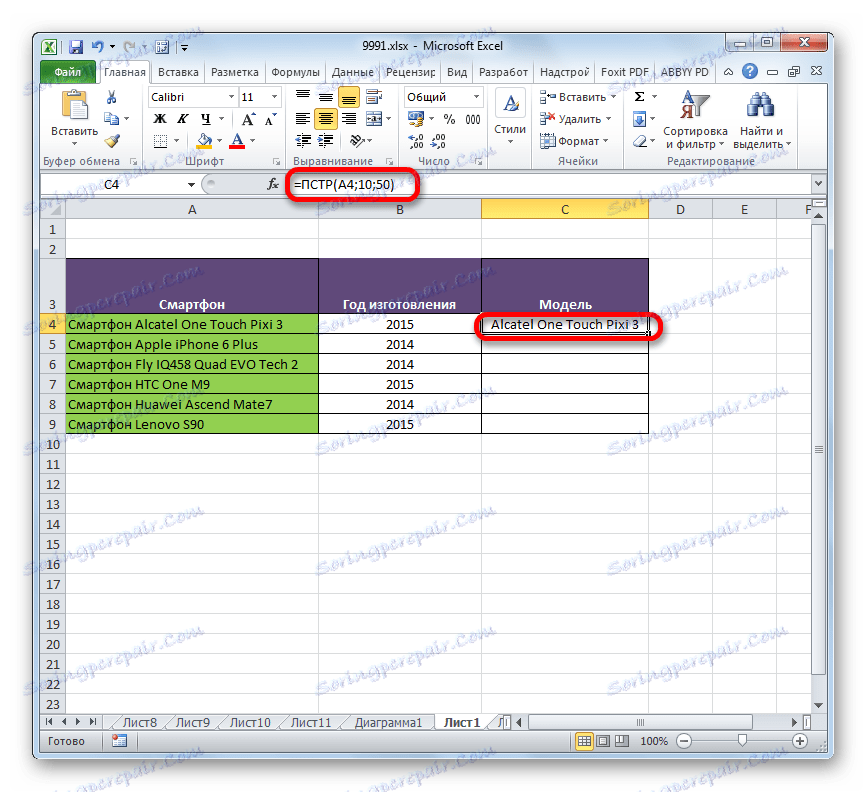
Po zadání dat klikněte na tlačítko "OK" .
- Poté se název prvního modelu smartphonu zobrazí v předem určené buňce tabulky.
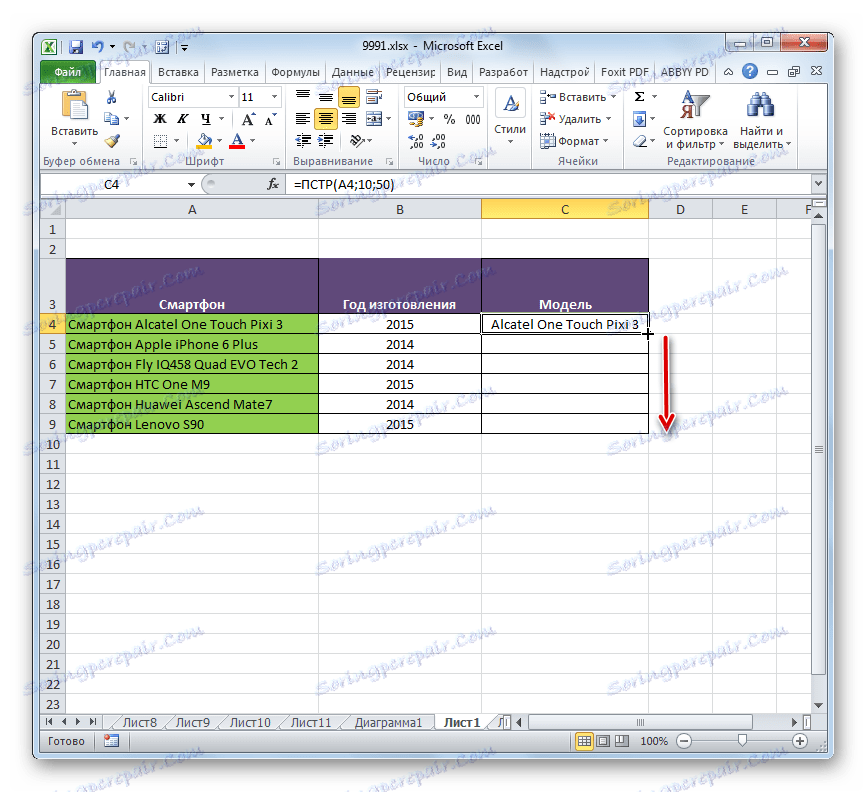
- Aby nebyl zadán vzorec v každé buňce sloupce samostatně, zkopírujeme jej pomocí značky naplnění. Chcete-li to provést, umístěte kurzor do pravého dolního rohu buňky vzorec. Kurzor je převeden na rukojeť výplně ve tvaru malého kříže. Slepte levým tlačítkem myši a přetáhněte jej na konec sloupce.
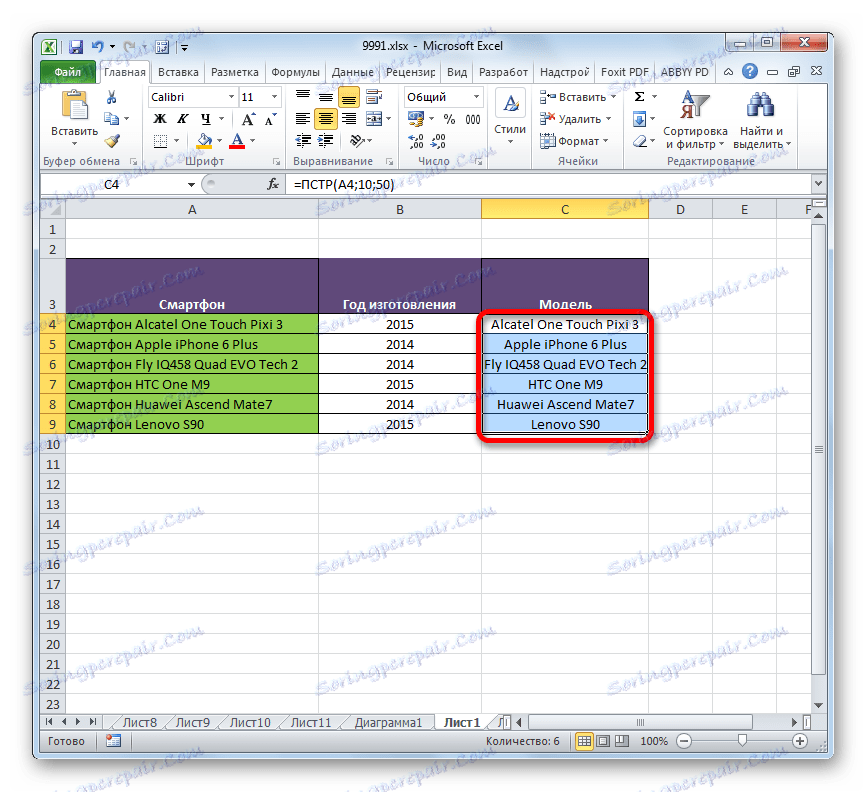
- Jak vidíte, celý sloupec bude poté vyplněn údajem, který potřebujeme. Tajemství spočívá v tom, že argument "Text" je relativní odkaz a také se mění vzhledem k změně polohy cílových buněk.
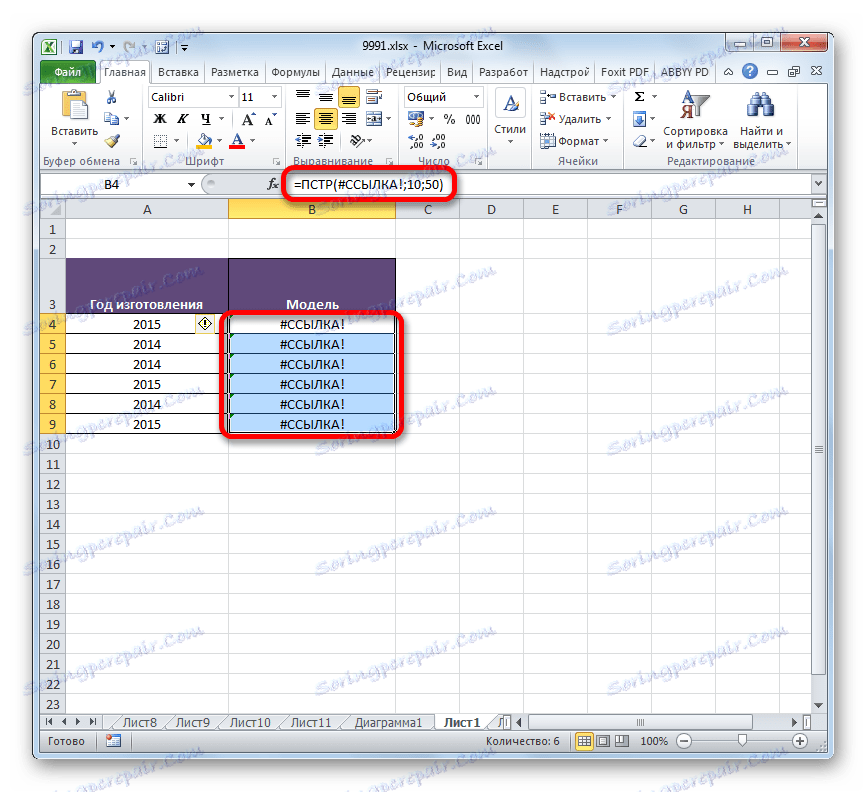
- Problém je však v tom, že pokud se rozhodneme náhle změnit nebo vymazat sloupec s původními daty, data v cílovém sloupci se zobrazí nesprávně, protože jsou navzájem spojeny vzorecem.
![Nesprávné zobrazení dat v aplikaci Microsoft Excel]()
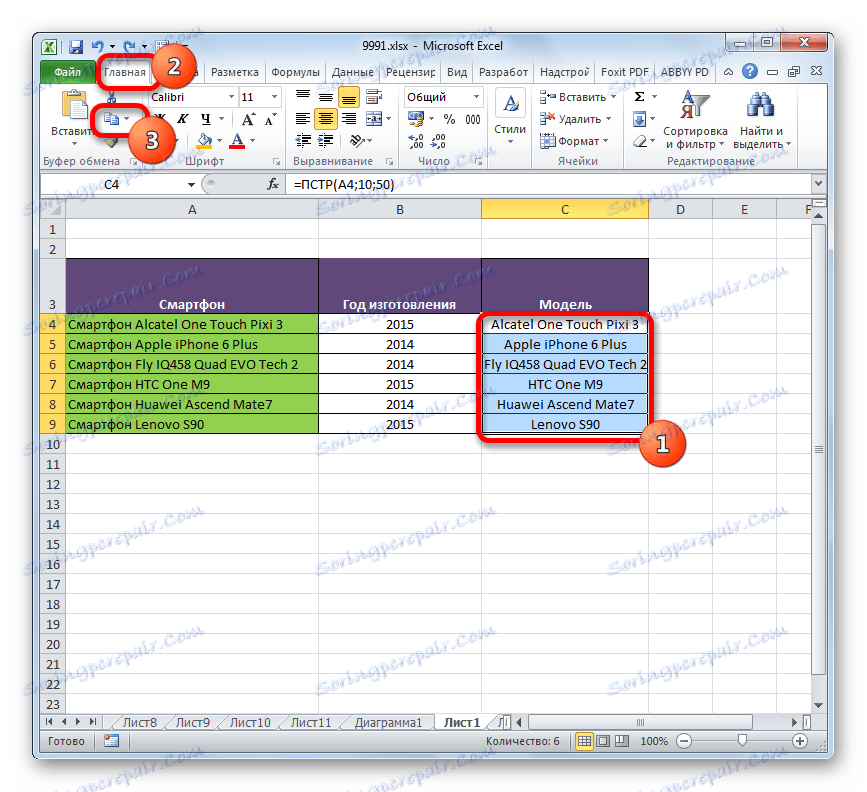
Chcete-li "oddělit" výsledek z původního sloupce, provádíme následující manipulace. Vyberte sloupec obsahující vzorec. Poté přejděte na kartu "Domov" a klikněte na ikonu "Kopírovat" umístěnou v bloku "Schránka" na pásu karet.
![Kopírování do aplikace Microsoft Excel]()
Jako alternativní akci můžete po výběru stisknout klávesy Ctrl + C.
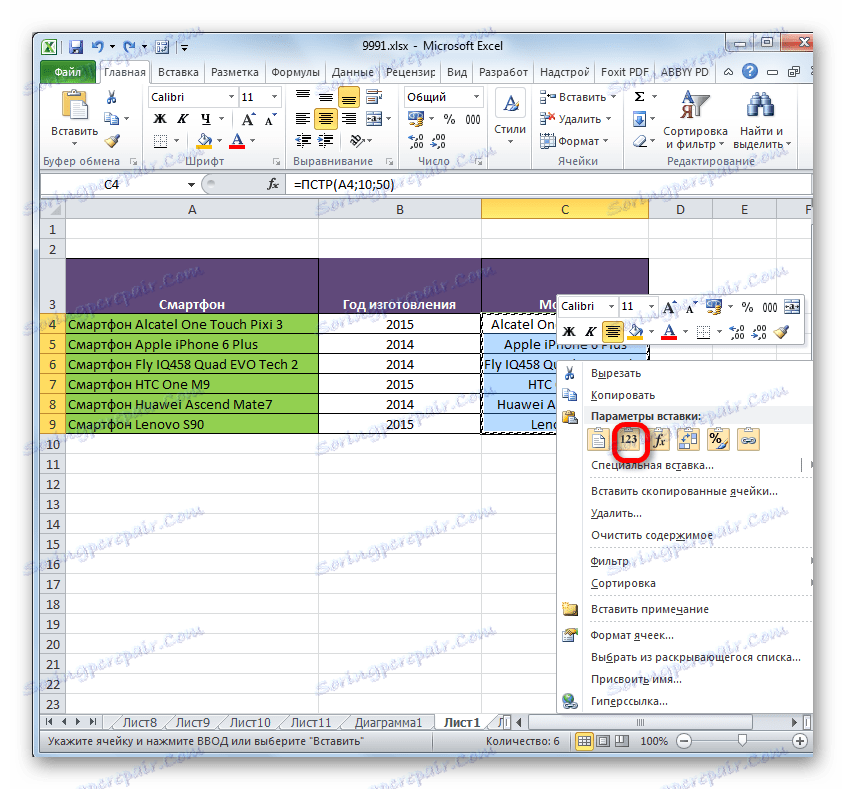
- Poté bez výběru zrušíte kliknutím na sloupec pravým tlačítkem myši. Otevře kontextovou nabídku. V bloku "Parametry vložení" klikněte na ikonu "Hodnoty" .
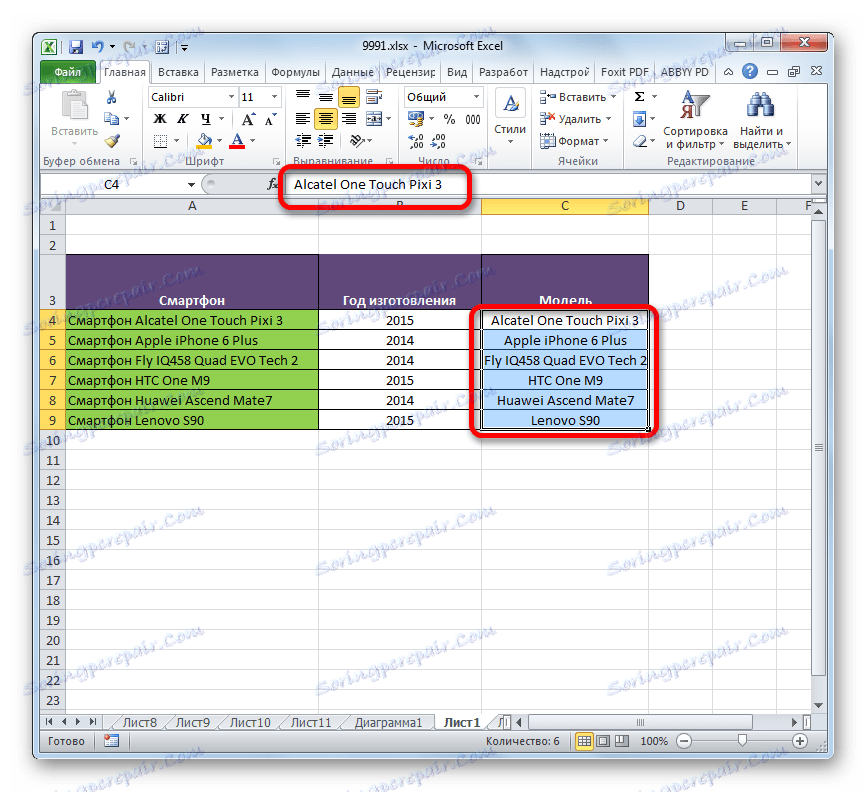
- Pak budou namísto vzorců vloženy hodnoty ve vybraném sloupci. Nyní můžete bezpečně upravit nebo odstranit původní sloupec. Výsledek není nijak ovlivněn.
Příklad 3: Použití kombinace operátorů
Ale přesto je výše uvedený příklad omezen na skutečnost, že první slovo ve všech zdrojových buňkách musí mít stejný počet znaků. Použití funkce SEARCH nebo SEARCH spolu s funkcí CCT výrazně rozšíří možnosti použití vzorce.
Textoví operátoři VYHLEDÁVÁNÍ a HLEDAT vrátí pozici zadaného znaku v zobrazeném textu.
Syntaxe funkce SEARCH je následující:
=ПОИСК(искомый_текст;текст_для_поиска;начальная_позиция)
Syntaxe operátora FIND vypadá takto:
=НАЙТИ(искомый_текст;просматриваемый_текст;нач_позиция)
Z velké části jsou argumenty těchto dvou funkcí totožné. Jejich hlavní rozdíl spočívá v tom, že operátor SEARCH nezohledňuje případ písmen při zpracování dat a HLEDÁ - bere v úvahu.
Podívejme se, jak používat operátor SEARCH ve spojení s funkcí CCR . Máme tabulku, ve které jsou zadávány názvy různých modelů výpočetní techniky se všeobecným názvem. Stejně jako v minulosti potřebujeme extrahovat jména modelů bez obecného jména. Obtížnost spočívá v tom, že pokud v předchozím příkladě byl stejný název všech položek stejný ("smartphone"), pak je v tomto seznamu odlišný ("počítač", "monitor", "sloupce" atd.). s různým počtem znaků. K vyřešení tohoto problému potřebujeme také operátor SEARCH , který budeme investovat do funkce CCT.
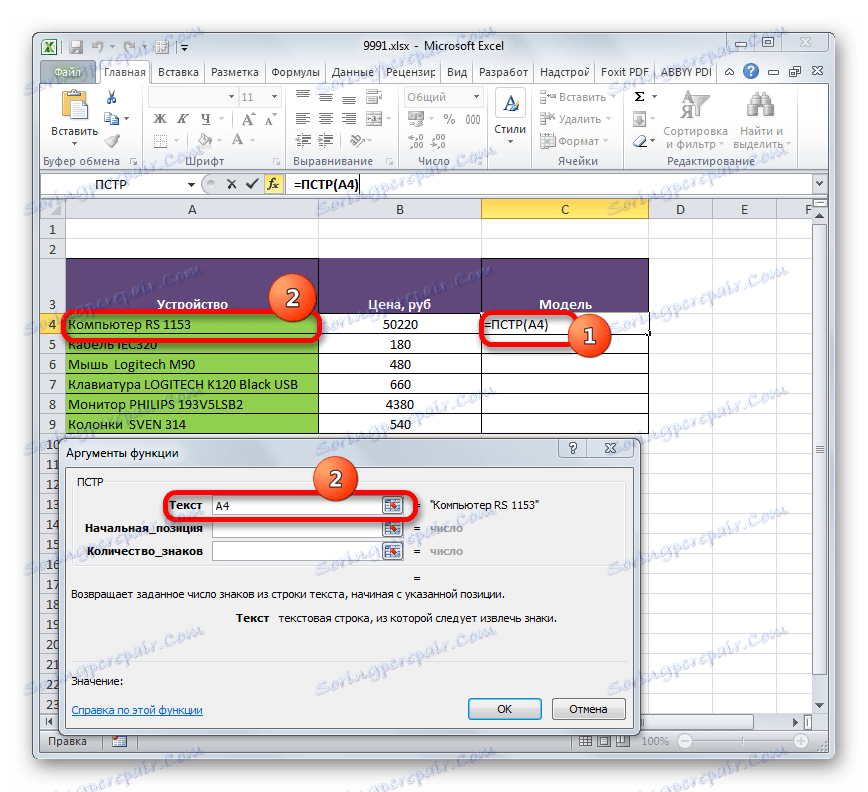
- Vybíráme první buňku sloupce, ve kterém budou data vygenerována, a obvyklým způsobem nazýváme okno argumentu funkce CCT .
V poli "Text" , jako obvykle, specifikujeme první buňku sloupce s původními daty. Zde je všechno nezměněno.
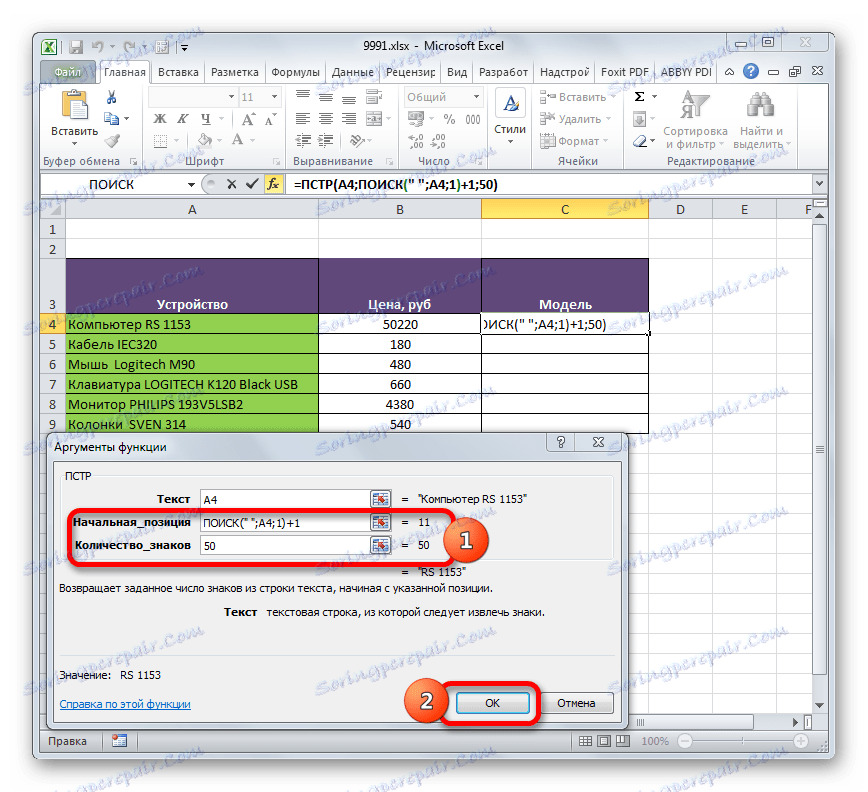
- Hodnota pole Počáteční pozice však určí argument, který vygeneruje funkce SEARCH . Jak vidíte, všechna data na seznamu jsou spojena skutečností, že před názvem modelu je mezera. Operátor SEARCH tedy vyhledá první mezera v buňce původního rozsahu a oznámí číslo tohoto symbolu do funkce CCT .
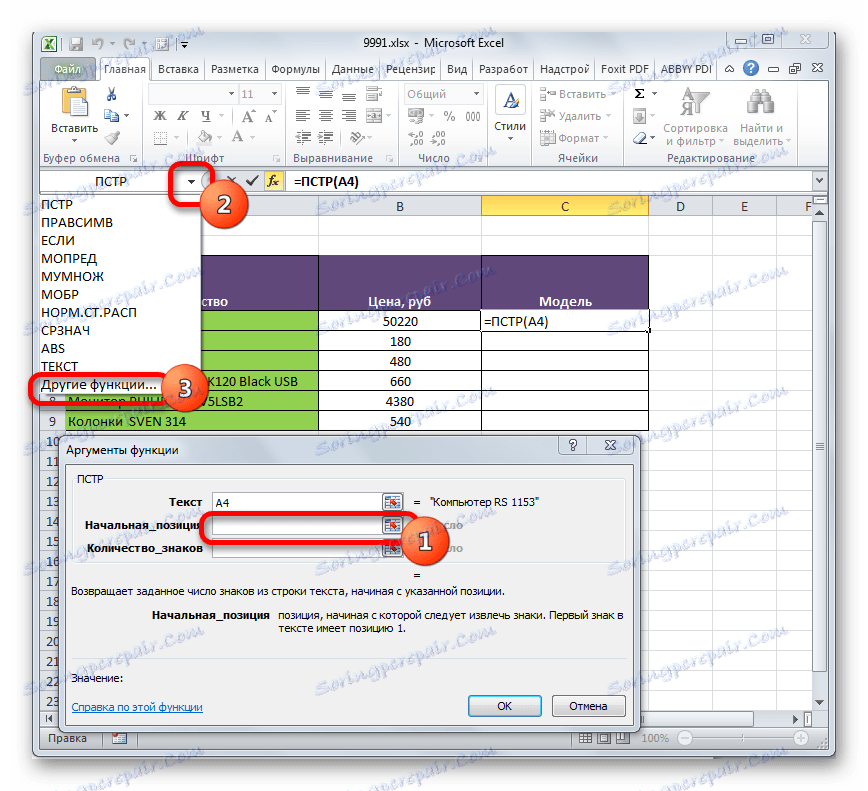
Chcete-li otevřít okno argumentů operátoru SEARCH , nastavte kurzor do pole "Počáteční pozice" . Dále klikněte na ikonu ve tvaru trojúhelníku směřujícího dolů. Tato ikona se nachází na stejné horizontální úrovni okna, kde se nachází tlačítko "Vložit funkci" a lištu vzorců, ale nalevo od nich. Zobrazí se seznam naposledy použitých operátorů. Jelikož mezi nimi neexistuje jméno "SEARCH" , klikněte na položku "Other functions ..." .
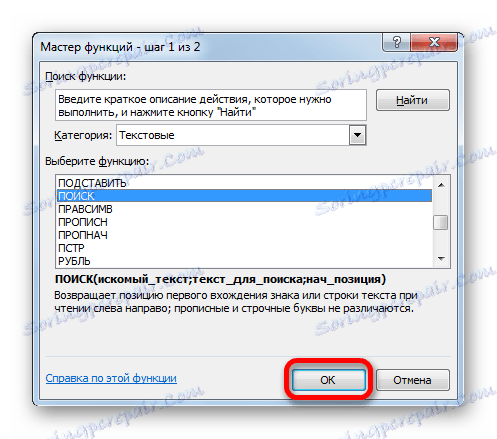
- Otevře se okno Průvodci . V kategorii "Text" vyberte název "SEARCH" a klikněte na tlačítko "OK" .
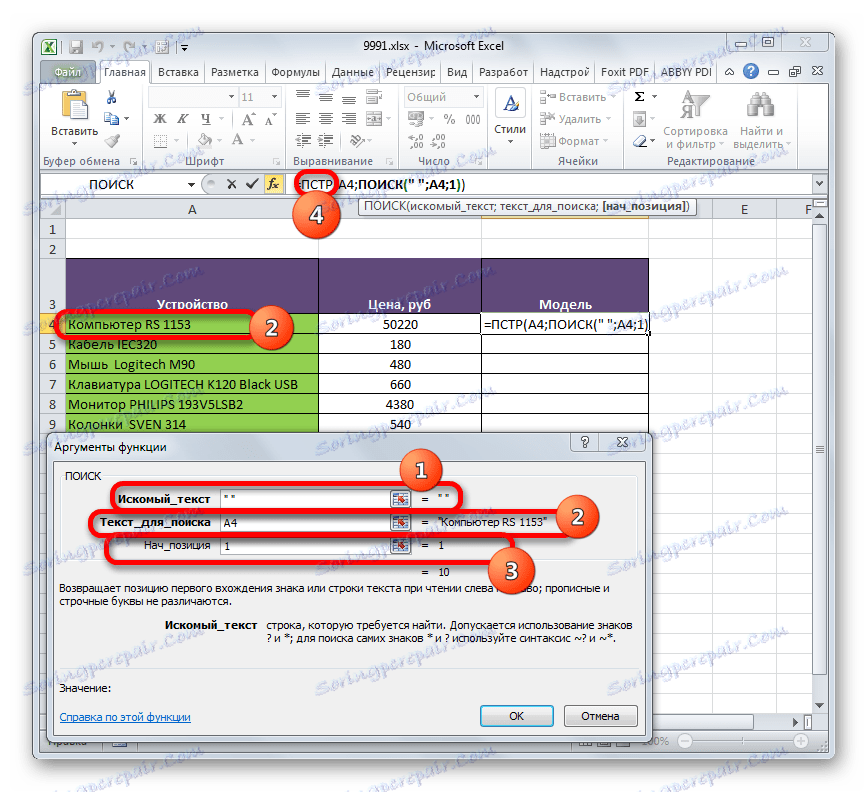
- Okno pro vyhledávače se otevře. Vzhledem k tomu, že hledáme prostor, vložili jsme místo do pole "Vyhledávací text" nastavením kurzoru a stisknutím odpovídajícího tlačítka na klávesnici.
V poli "Text pro vyhledávání" specifikujeme odkaz na první buňku sloupce s původními daty. Tento odkaz bude stejný jako ten, který jsme dříve označili v poli "Text" v okně s argumenty operátora BTS .
Pole "Počáteční poloha" je volitelná. V našem případě není nutné jej vyplnit, nebo můžete nastavit číslo "1" . Pro každou z těchto možností bude vyhledávání provedeno od začátku textu.
Po zadání dat nezapomeňte stisknout tlačítko "OK" , protože je vnořena funkce SEARCH . Jednoduše klikněte na název PCR ve vzorci.
- Po provedení poslední zadané akce se automaticky vrátíme do okna argumentů operátora BTS . Jak vidíte, pole "Počáteční pozice" je již vyplněno vzorem SEARCH . Tento vzorec však označuje prostor a po prostoru, ze kterého začíná název modelu, potřebujeme další znak. Proto k existujícím údajům v poli "Počáteční pozice" přidáme výraz "+1" bez uvozovek.
V poli "Počet znaků" , jako v předchozím příkladu, zapisujeme libovolné číslo, které je větší nebo rovné počtu znaků v nejdelším výrazu původního sloupce. Například zadejte číslo "50" . V našem případě to stačí.
Po provedení všech uvedených manipulací klikněte na tlačítko "OK" ve spodní části okna.
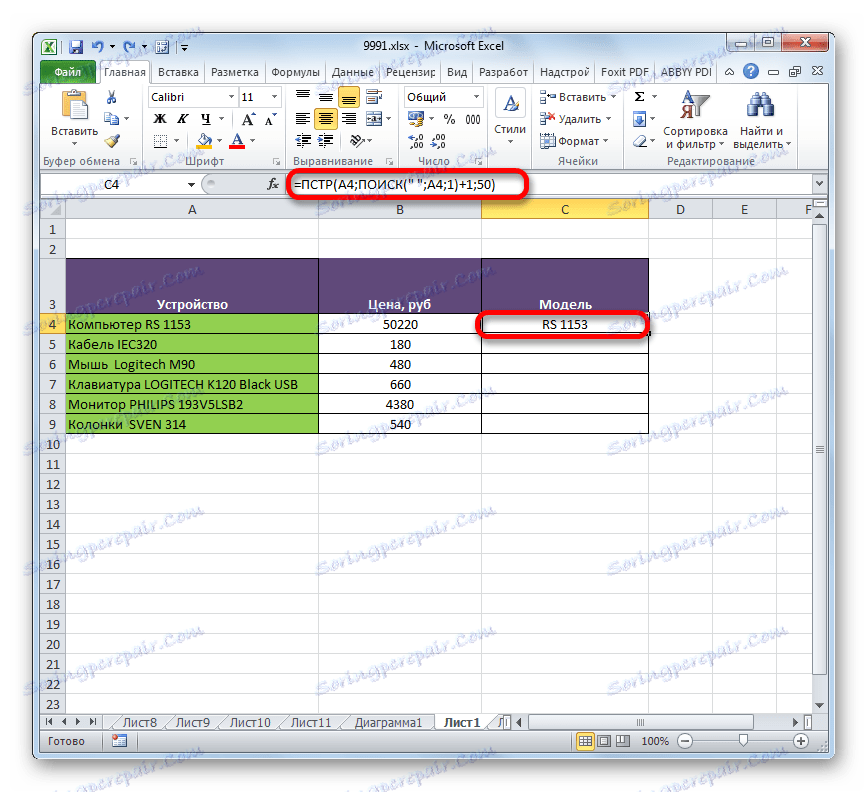
- Jak můžete vidět, poté byl název modelu zařízení zobrazen v samostatné buňce.
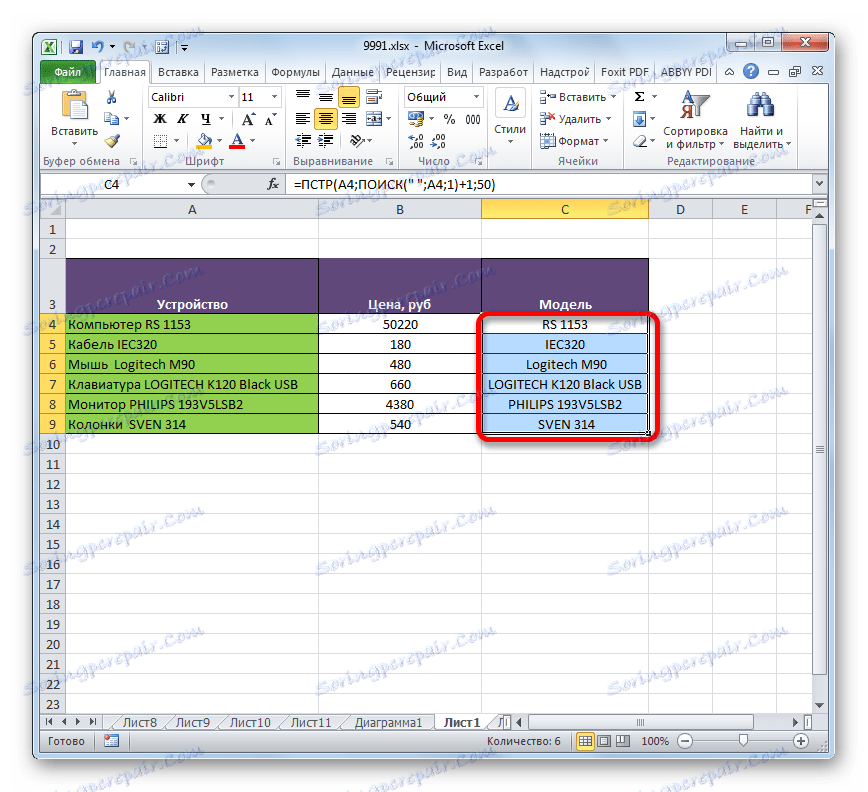
- Nyní pomocí Průvodce vyplněním, jako v předchozí metodě, zkopírujte vzorec do buněk, které jsou umístěny dolů v tomto sloupci.
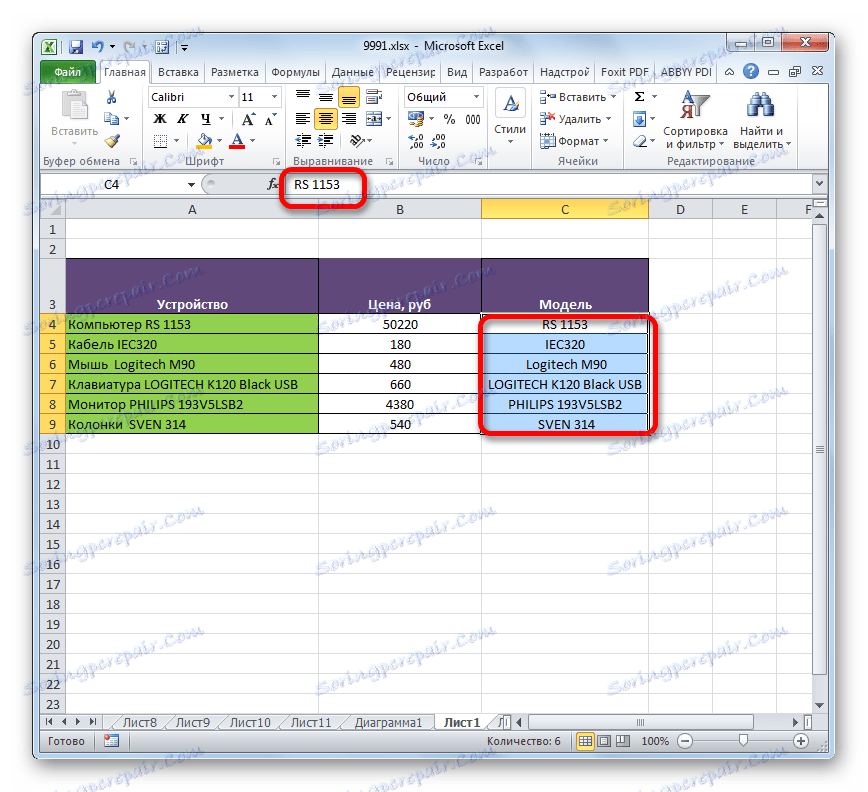
- Názvy všech modelů zařízení se zobrazují v cílových buňkách. Nyní, je-li to nutné, je možné v těchto prvcích oddělit sloupec původních dat, stejně jako v předchozím čase, postupným kopírováním a vkládáním hodnot. Tato akce však není vždy povinná.
Funkce FIND se používá ve spojení s formulacem EPR stejným principem jako operátor SEARCH .
Jak je vidět, funkce PCR je velmi vhodným nástrojem pro zobrazování potřebných dat v předem určené buňce. Skutečnost, že není mezi uživateli tak populární, je vysvětlena skutečností, že mnoho uživatelů, kteří používají aplikaci Excel, věnuje více pozornosti matematickým funkcím než textům. Při použití tohoto vzorce v kombinaci s jinými operátory se jeho funkce dále zvyšuje.